
티스토리 뷰
들어가며
국민대 산학 협력 프로젝트에서 토픽 별 감정 분석 / 평점 예측을 진행하는데, 기존 LDA나 Topic Modeling 방식의 분석의 성능이 미진하여 LLM으로 시도하기 위해 LLM에 대해 조사하였다.
OpenAI API
https://platform.openai.com/account/usage

위 링크에서 OpenAI의 API는 18$을 무료로 제공하는 것을 확인할 수 있다.
https://openai.com/pricing#language-models
위 링크에서 OpenAI에서 제공하는 모델들의 가격을 확인할 수 있다. 언어 모델만 확인해보자면 다음과 같다.
우가 바라는 파인튜닝에 관한 것은 기존엔 GPT-3 기반의 davinci, curie, babbage, ada만 파인튜닝이 가능하다고 했으나 곧 저 기존 모델들의 지원을 중단하고 GPT-3 기반 모델을 업그레이드 하고 GPT-3.5 Turbo, GPT-4를 지원할 예정으로 보인다. 아직 정식 지원한다는 얘기는 아니고 예정만 돼 있는 듯 하다.
OpenAI에서도 기존 모델들을 사용하기보다 새로 옵션이 나올때까지 기다리는 것을 추천하기 때문에 당장에는 다른 모델들을 활용하는 것이 더 나아보인다.
파인튜닝은 아니지민 GPT-3.5 turbo를 프롬프트 엔지니어링 하여 토픽 별 감정 분석한 예제를 찾을 수 있었다.
PALM API
구글에서 제공하는 API로 PALM2 모델을 사용할 수 있다. 기본적으로는 구글 클라우드 플랫폼의 vertex ai로 사용하는 것 같으며 Scikit-LLM으로 손쉽게 파인튜닝할 수 있다. 가격은 공식적인 문서는 찾지 못했으나 어떤 블로그에선 bison 모델이면 1000자(토큰 아님)당 text 모델의 경우 0.001$, chat 모델의 경우 0.0005$이라고 한다.
Scikit-LLM을 활용하여 튜닝하는 예시
from skllm.models.palm import PaLM
X = ["Tell us something about Scikit-LLM" for _ in range(20)]
y = ["Scikit-LLM is awesome" for _ in range(20)]
model = PaLM(n_update_steps=100)
model.fit(X, y)
labels = model.predict(["Tell us something about Scikit-LLM"])
print(labels[0])
# > Scikit-LLM is awesome
영상으로 구글 클라우드로 커스텀 모델을 학습하는 방법도 알려준다. 다만 PALM API는 구글 클라우드 플랫폼이라는 복잡한 생태계 떄문에 사용하려면 공부가 더 필요할 것 같다.
https://www.youtube.com/watch?v=4A4W03qUTsw
https://medium.com/google-cloud/generative-ai-getting-started-with-palm2-91a8354beeff
https://medium.com/@iryna230520/fine-tune-google-palm-2-with-scikit-llm-d41b0aa673a5
다른 오픈소스 LLM
Llama 2
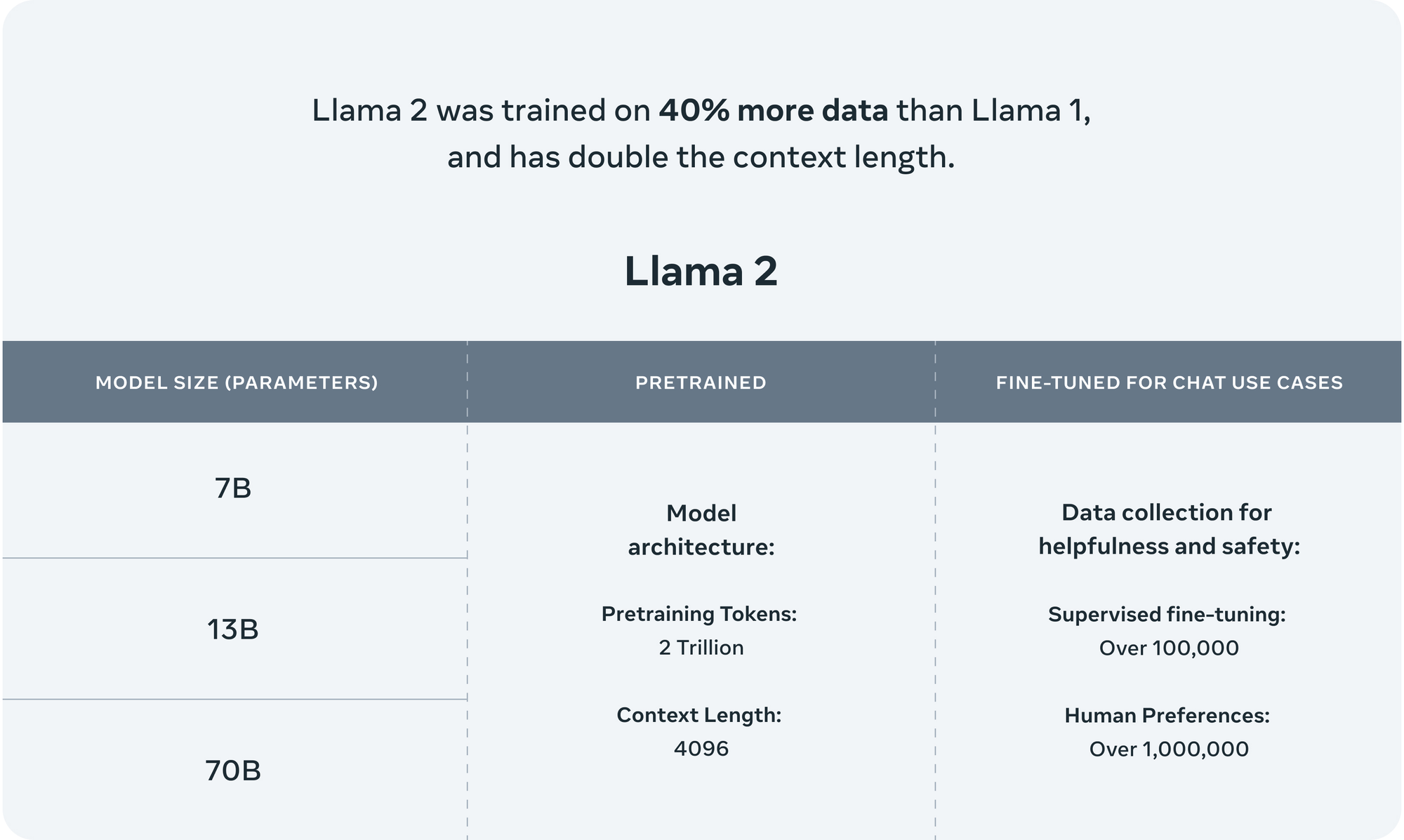
메타에서 공개한 라마의 후속 모델로 70B 모델이 GPT-3.5와 비슷한 성능을 낸다고 한다. 이 모델은 완전 무료, 상업 목적으로도 사용 가능하다.
이 라마 모델을 활용하는 방법은 두 가지인데, 첫 번째는 라마의 공식 사이트를 이용하는 방법, 두 번째 방법은 허깅페이스를 통하는 방법이다.
https://ai.meta.com/resources/models-and-libraries/llama-downloads/
위 링크는 라마 공식 다운로드 사이트고 링크에 들어가서 라이센스 동의하고 신청하면 다운로드 링크를 받는다고 한다.
https://huggingface.co/meta-llama
위 링크는 허깅페이스의 라마 링크이다. 아래 인덱스에서 원하는 모델 링크를 누르고 동의하면 몇 시간 후 이용할 수 있다고 한다.

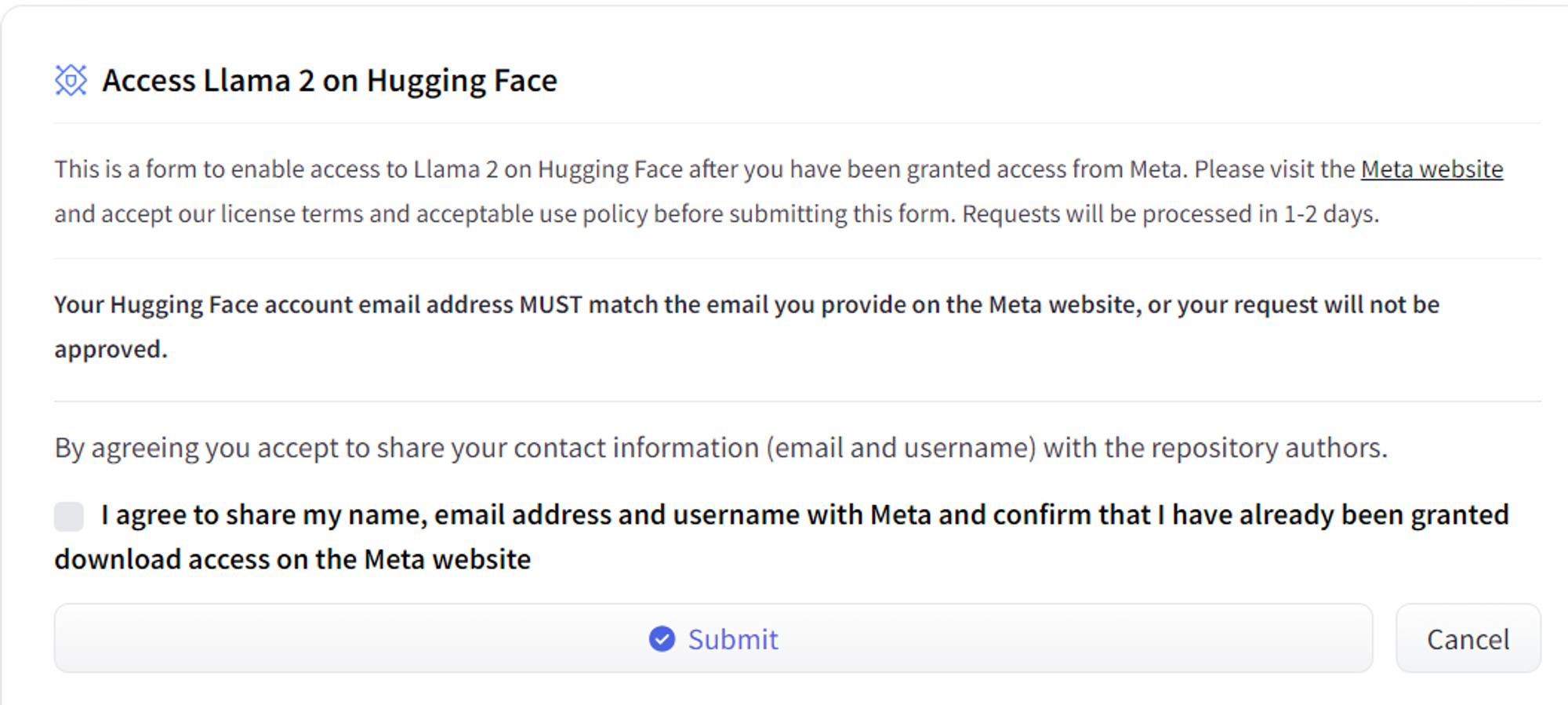
인덱스에서 뒤에 hf가 붙어있는 모델은 허깅페이스 라이브러리를 통해 이용할 수 있는 모델이고 붙어있지 않은 것은 파이토치 체크포인트(pth) 파일이다.
그리고 chat이 붙지 않은 것은 Text Completion, 붙은 것은 Chat Completion 모델이다.
Text Completion은 문장이 입력으로 들어왔을 때 그 문장의 뒤를 이어주는 모델이고, Chat Completion은 ChatGPT처럼 채팅처럼 주고받는 형식의 모델이다.
7B 모델을 돌릴 때는 적어도 15GB의 VRAM이 필요하다.
Alpaca
LLaMA 7B 모델을 파인튜닝한 모델로 GPU 하나로 돌릴 수 있을만큼 가볍다. 짧은 답변으로 파인튜닝되어 일반적으로 GPT 3.5 보다 답변이 짧다고 한다.
파인튜닝 하는 방법은 다음 링크에 잘 나와있다.
https://www.mlexpert.io/machine-learning/tutorials/alpaca-fine-tuning
라마와 알파카를 LoRA로 파인튜닝 감정분석 모델을 만드는 포스트이다.
파인튜닝 기법은 적은 리소스로 최대한의 효과를 위해 PEFT 중 LoRA 기법을 많이 활용하는 것 같다.
PEFT(Parameter-Efficient Fine-Tuning)은 대부분의 파라미터를 프리징하고 일부의 파라미터만을 파인튜닝하여 저장공간과 계산량을 대폭 줄인다.
다른 모델들로 Vicuna나 GPT4ALL도 있었으나 활용 방법은 대동소이한 것 같다.
LLM Finetuning
LLM 파인튜닝에 대한 기본적인 개념을 다음 포스트에서 잘 정리해 둔 것 같아 내용을 정리해 보았다.
https://bdtechtalks.com/2023/07/10/llm-fine-tuning/
Repurpose LLM
GPT와 같은 LLM 제품군은 임베딩을 사용하여 토큰이나 텍스트를 생성한다. 만약 분류로 용도 변환을 하고자 한다면 LLM의 어텐션 레이어는 고정하고 어텐션 레이어에서 생성된 임베딩만을 이용하여 classifier를 학습하면 된다.
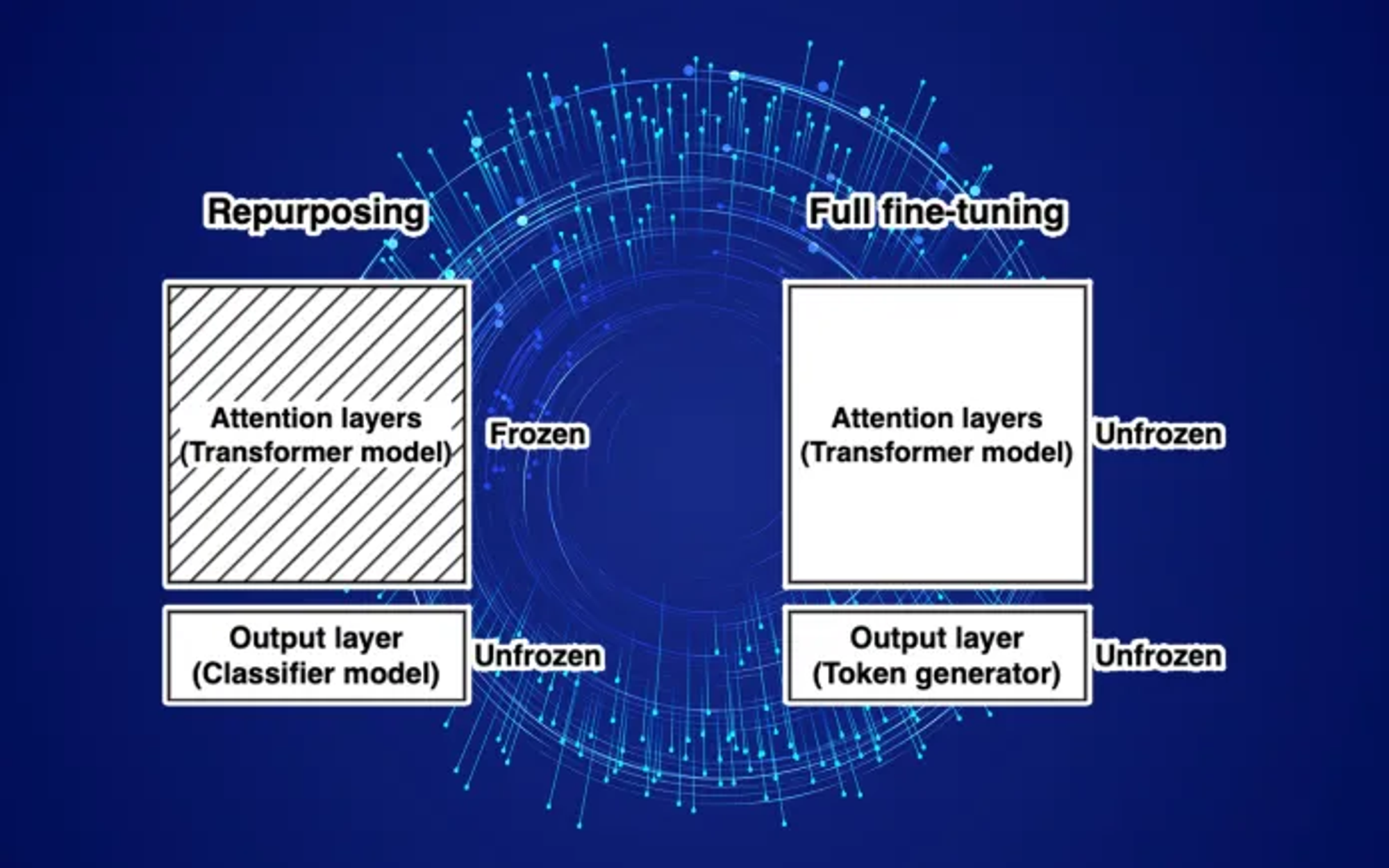
Unsupervised / Self-Supervised Learning
LLM에 의학 지식이나 다른 언어 같은 지식을 업데이트 하고싶다면 의학 저널같은 unstructed dataset으로 충분한 토큰을 하게 하면 된다. 이 경우는 모델에 따라 unsupervised 혹은 self-supervised learning이라 한다.
Instruction Fine-tuning
단순히 새로운 정보를 학습시키는 데에 그치지 않고 LLM의 행동 자체를 바꾸고 싶다면 supervised fine-tuning (SFT) dataset으로 학습한다. SFT dataset은 프롬프트와 그에 해당하는 답변의 집합이다. SFT dastaset은 사람이 수동으로 만들거나 다른 LLM으로 생성한다. 이 경우는 instruction fine-tuning이라 한다.
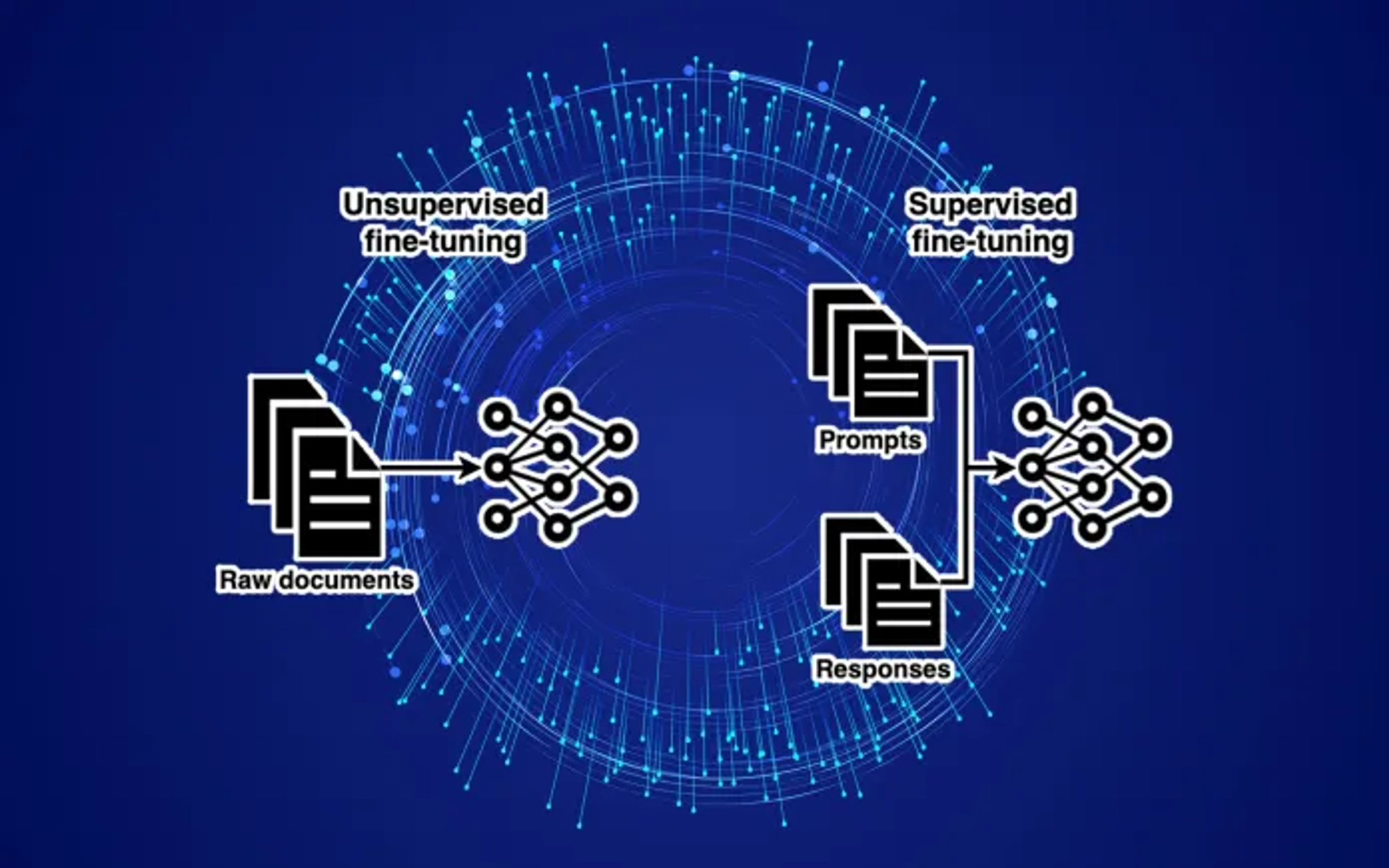
Reinforcement learning from human feedback (RLHF)는 여기서 한 발 더 나아가 사람에게 모델이 프롬프트에서 생성한 답변을 평가하도록 하는 것이다. 그리고 모델은 high-rating 결과를 내도록 파인튜닝한다.
Parameter-efficient fine-tuning (PEFT)
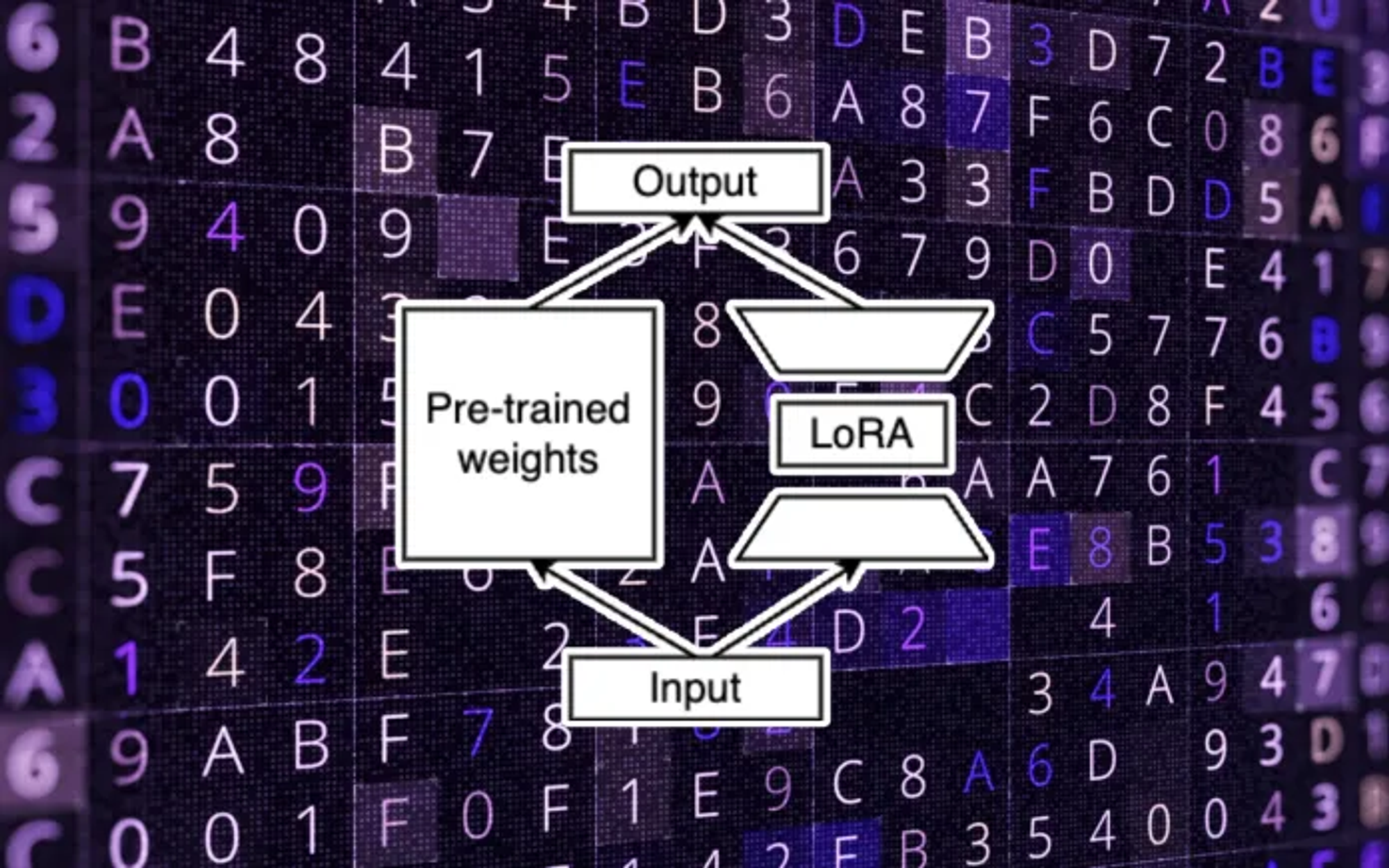
LLM은 파인ㅌ튜닝하기에는 너무 비싸기 때문에 PEFT로 업데이트할 파라미터를 줄인다. 대표적인 PEFT 기법으로는 low-rank adaption(LoRA)가 있다. LoRA의 아이디어는 다운스트림 작업을 높은 정확도로 나타내는 공간의 low-dimention matrix가 있기 때문에 기반 모델이 다운스트림 할 때 모든 파라미터를 업데이트 할 필요가 없다는 것이다.
LoRA로 파인튜닝한다는 것은 LLM 파라미터를 업데이트하는 것이 아니라 low-rank matrix를 학습하는 것이다. 학습된 LoRA 모델의 파라미터 가중치는 추론시에 LLM에 통합되거나 더해진다.
In-context learning / retrieval augmentation
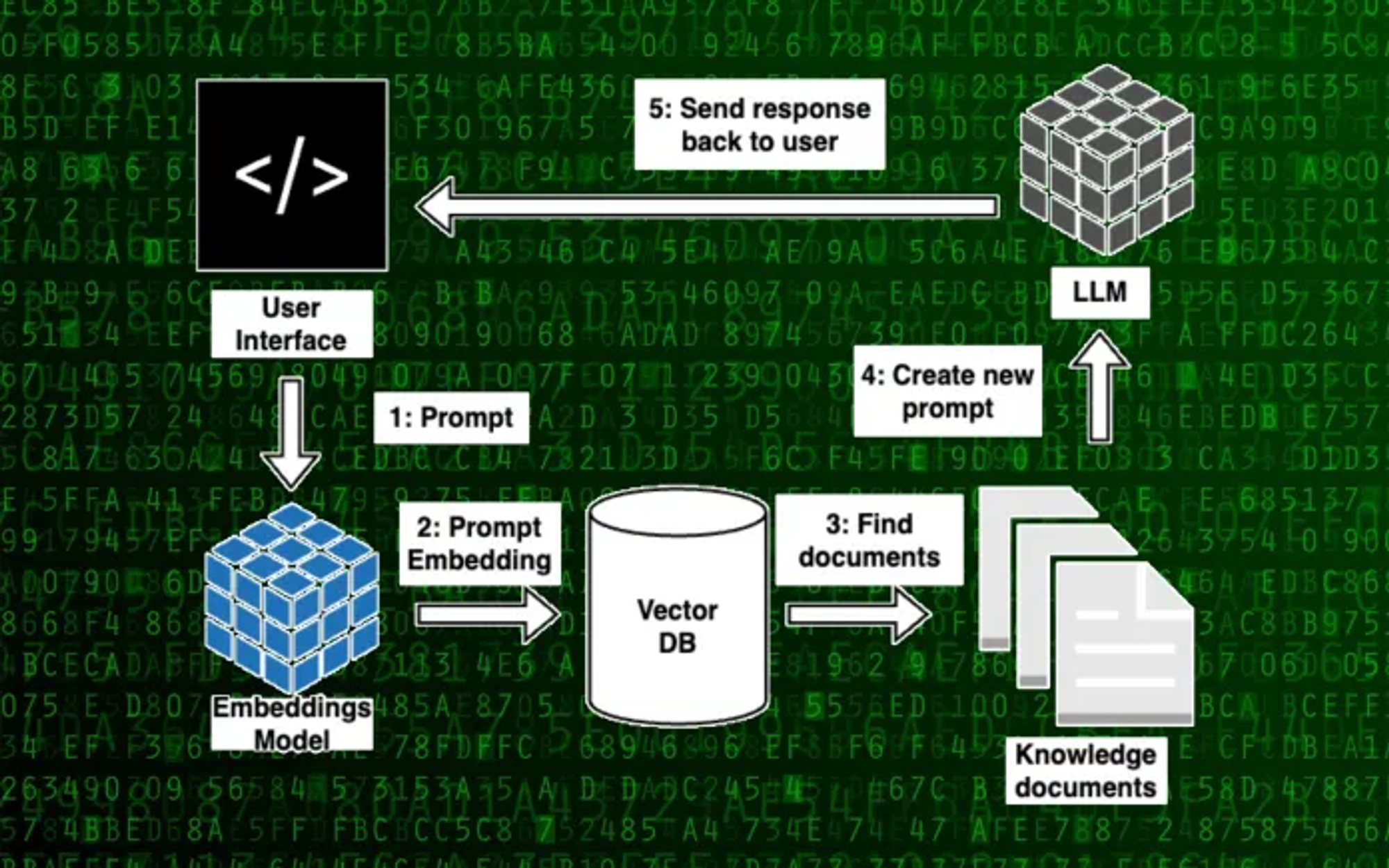
추론시에 모델에 맥락을 전해주는 것이다. LLM이 글을 쓰길 바란다면 프롬프트 앞에 뉴스 리포트나 위키피디아 페이지 같은 연관 문서를 추가하는 것이다. 다른 예시로 LLM이 유저에 특화된 답변을 제공해야 한다면 프롬프트를 입력할 때 앞에 유저의 재무 데이터, 건강 데이터 같은 유저 정보를 입력하여 모델을 조작할 수 있다.
좀 더 고도화 된 방법으론 맥락으로 사용할 정보의 임베딩을 데이터베이스에 저장하는 것이다. 유저가 프롬프트를 입력할 때 DB에서 연관 문서를 검색하고 모델에 맥락 정보를 전달한다.
'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| SetFit 조사 및 distilbert와 sentiment analysis 성능 비교 (1) | 2023.08.19 |
|---|---|
| llama2 다운 및 파인튜닝 (7) | 2023.08.07 |
| 텍스트 분석 - 텍스트 전처리 (0) | 2023.06.27 |
| [논문 리뷰]Hierarchical Attention Prototypical Networks for Few-Shot Text Classification (0) | 2023.05.19 |
| 추천 시스템 (0) | 2023.05.15 |