
티스토리 뷰
SetFit
https://huggingface.co/blog/setfit
https://arxiv.org/abs/2209.11055
SetFit 개요
SetFit은 Sentence Transformer*를 few-shot에서 효율적인 파인튜닝을 위한 프레임워크이다. 이 프레임워크를 이용하면 고객 리뷰 감정 분석에서 8개의 샘플로 학습한 것과 RoBERTa Large로 3천 샘플 학습한 것과 비견될 정도라고 한다.
SetFit은 다른 few-shot 러닝 방법들과 비교했을 때 다음의 이점을 갖는다.
- 프롬프트나 해설자(verbalisers)가 필요가 없다.
- SetFit은 GPT같이 큰 모델을 사용할 필요가 없기 때문에 학습과 추론에서 이점을 갖는다.
- SetFit은 허깅페이스 허브에 있는 어떤 Sentence Transformer나 사용해도 되기 때문에 확장성이 좋다.
※ Sentence Transformer는 문장, 텍스트, 이미지를 임베딩하는 프레임워크라고 한다.
SetFit 작동법
SetFit은 두 단계를 거친다. 처음엔 Sentence Transformer 모델을 적은 수의 라벨링 예제(8, 16개)로 파인튜닝 한 다음 여기서 생성된 임베딩으로 분류기를 학습한다.
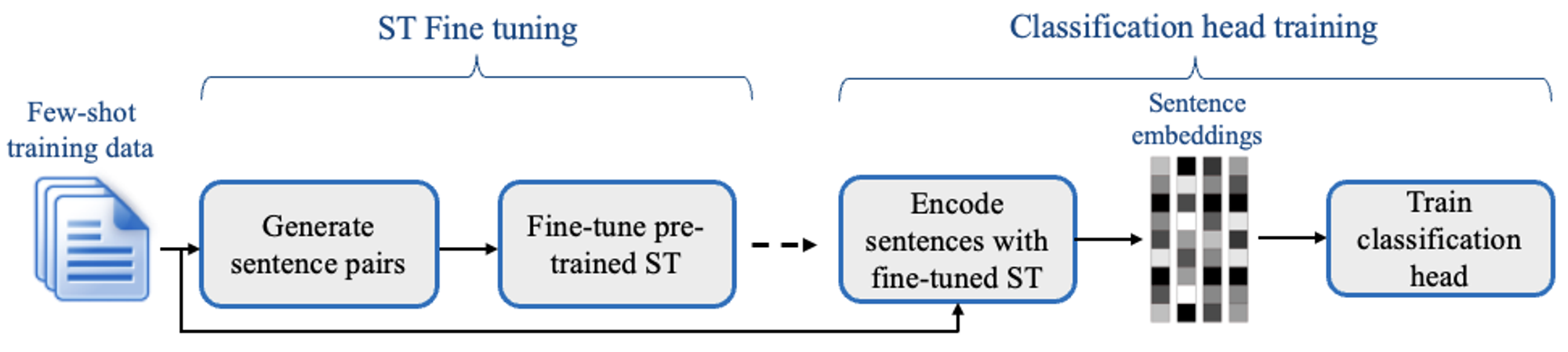
ST Fine tuning
Sentence Transformer를 파인 튜닝 할 때 제한된 학습 데이터를 더 잘 다루기 위해서 대조 학습법(contrastive training approach)을 채택했다. 이 학습법을 간단하게 설명하자면 서로 같은 클래스의 데이터는 가까이 임베딩 되고, 다른 클래스는 멀리 임베딩 되도록 학습하는 것이다.
동일한 클래스끼리 묶어 positive set을 만들고 서로 다른 셋을 묶어 negative set을 만들어 각각 1, 0의 레이블을 주고 이진 분류를 하도록 한다.
Classification head training
단순하게 임베딩 된 값을 원하는 클래스로 예측하도록 분류기를 학습시킨다.
성능



종합적으로 약간의 성능 타협으로 매우 효과적인 few-shot 학습이 가능하다.
다음은 허깅 페이스를 이용해 yelp_polarity 데이터셋으로 리뷰 감정 분석하는 예제다. 원래 예제와 다른 점은 코랩의 VRAM 용량상 paraphrase-mpnet-base-v2가 올라가지 않아서 sentence transformers 모델 중 msmarco-distilbert-base-tas-b를 이용하였다.
pip install setfitfrom datasets import load_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
dataset = load_dataset("yelp_polarity")
# Select N examples per class (8 in this case)
train_ds = dataset["train"].shuffle(seed=42).select(range(8 * 2))
test_ds = dataset["test"]
# Load SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/msmarco-distilbert-base-tas-b")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_ds,
eval_dataset=test_ds,
loss_class=CosineSimilarityLoss,
batch_size=16,
num_iterations=20, # Number of text pairs to generate for contrastive learning
num_epochs=1 # Number of epochs to use for contrastive learning
)
# Train and evaluate!
trainer.train()
metrics = trainer.evaluate()
결과는 약 72%의 정확도가 나왔다. 그러나 데이터 전체를 파인튜닝하는 경우에 비교하여 얼마나 뛰어난지 비교하기 위해 distilbert 모델을 통해 파인튜닝을 진행해 보았다.
DistilBERT Classifiaction
PEFT Sequence Classification 예시 코드https://huggingface.co/docs/peft/main/en/package_reference/peft_model#peft.PeftModelForSequenceClassification
Text Classification 예시 코드
https://huggingface.co/docs/transformers/tasks/sequence_classification
위 두 코드를 참고해서 PEFT로 DistilBERT를 학습하였다.
필요 라이브러리 설치
pip install transformers datasets peft evaluate
pip install accelerate -U
필요 라이브러리 import
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer, AutoTokenizer, DataCollatorWithPadding
from datasets import load_dataset
from peft import PeftModelForSequenceClassification, get_peft_config, PromptEncoderConfig, get_peft_model, LoraConfig, TaskType
import numpy as np
import evaluate데이터 처리
dataset = load_dataset("yelp_polarity")
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
id2label = {0: "NEGATIVE", 1: "POSITIVE"}
label2id = {"NEGATIVE": 0, "POSITIVE": 1}모델 구성
num_labels = 2 # replace with the actual number of labels in your classification task
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=num_labels, id2label=id2label, label2id=label2id)
config = {
"peft_type": "PREFIX_TUNING",
"task_type": "SEQ_CLS",
"inference_mode": False,
"num_virtual_tokens": 20,
"token_dim": 768,
"num_transformer_submodules": 1,
"num_attention_heads": 12,
"num_layers": 12,
"encoder_hidden_size": 512, # 원본 코드에서 768이었는데 데이터 모양 오류나서 512로 바꾸니 해결됨 / 왜 해결된지는 모름
"prefix_projection": False,
# "postprocess_past_key_value_function": None,
}
peft_config = get_peft_config(config)
peft_model = PeftModelForSequenceClassification(model, peft_config)
학습 인자 구성 및 학습
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
training_args = TrainingArguments(
output_dir="./",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
print(trainer.evaluate())

학습은 TITAN Xp 기준으로 4시간 정도 걸렸고 정확도는 약 91%가 나왔다. 확실히 56만개의 데이터를 다 학습시키는 편이 정확도가 훨신 높지만 데이터 샘플이 적을 때는 16개 샘플로 72%의 정확도를 보이는 SetFit이 훌륭한 대안이 될 수 있을 것 같다.
'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| [논문 리뷰]TinyOL: TinyML with Online-Learning on Microcontrollers (0) | 2023.11.08 |
|---|---|
| [논문 리뷰]TinyTL: Reduce Activations, Not Trainable Parameters for Efficient On-Device Learning (0) | 2023.11.08 |
| llama2 다운 및 파인튜닝 (7) | 2023.08.07 |
| LLM 조사 (0) | 2023.08.07 |
| 텍스트 분석 - 텍스트 전처리 (0) | 2023.06.27 |