
티스토리 뷰
[논문 리뷰]TinyOL: TinyML with Online-Learning on Microcontrollers
ProWiseman 2023. 11. 8. 12:45들어가며
본 글은 TinyOL: TinyML with Online-Learning on Microcontrollers을 리뷰한 글입니다.
기존 TinyML의 한계
모델이 컴퓨팅 파워가 강력한 머신이나 클라우드에서 학습되고 이후 엣지 기기에 업로드 될 것을 가정하기 때문에 MCU는 추론만 할 수 있으면 됐다. 이 전략은 모델을 정적 객체로 취급하여 새로운 데이터를 학습하기 위해선 처음부터 다시 학습한 다음 또 다시 MCU에 업로드 해 주어야 한다. 이 때문에 다음의 상황에서 문제가 된다.
- 접근하기 힘든 곳에 설치된 기기나 수많은 양의 모델을 업데이트 할 경우 비용이 많이 든다.
- 모든 머신은 서로 다르기 때문에 어떤 기기는 하나의 기기에서 수집된 데이터로 학습된 모델로는 잘 작동하지 않을 수 있음 (센서의 측정치가 기기별로 조금식 다른 것을 의미하는 것 같음)
- 임베디드 기기의 한계로 현장 데이터(field data)를 저장하기 힘듦
- 측정하는 환경은 지속적으로 변화하기 때문에 데이터 분포가 변하면 모델의 성능이 떨어질 수 있음 (concept drift)
TinyOL
TinyOL 특징
- 어떤 기존 네트워크든지 추가 레이어로써 적용할 수 있다.
- 기존 모델을 추론하는 도중에도 새로운 데이터를 online learning 세팅으로 가중치를 업데이트 할 수 있다.
- 레이어를 학습하거나 새로운 레이어 구조로 수정하여 새로운 데이터 클래스를 수용할 수 있다.
- incremental learning을 통해 과거 데이터를 저장할 필요가 없다.
- ※ incremental learning이란 데이터를 한 번에 학습하는 것이 아니라 순차적으로 학습하는 것이다. 예를 들어 1000개의 클래스의 데이터를 100개씩 10개 세트씩 학습/테스트를 진행한다. 이러면 1세트에서 본 데이터를 다음 9세트를 학습하는 동안 볼 수 없지만 최종 테스트에서도 잘 구별해야 한다. 출처
- 모델을 항상 최신 상태로 유지하여 concept drift를 해결한다.
TinyOL 시스템
TinyOL은 기존 MCU의 신경망에 새로운 레이어를 추가하거나 특정 레이어로 대체한다. TinyOL은 데이터 저장, 연산량 오버헤드같은 MCU의 여러 제약을 완화한다.
TinyOL의 핵심 컴포넌트는 Fig. 1에서 까맣게 칠해진 추가 레이어이다. 이 추가 레이어는 커스텀 가능한 뉴런으로 구성되어 있으며 실시간으로(on the fly) 업데이트 된다. 이는 기존 신경망의 새로운 출력 레이어로 취급된다.
기존 신경망은 MCU 플래시에 C 배열로 업로드 되어있기 때문에 고정된 그래프(frozen graph)로 취급되어 업로드 이후 수정 불가능 하지만 추가 레이어는 RAM에서 실행되기 때문에 학습될 수 있다.

다음 이미지는 TinyOL 파이프라인의 수도 코드이다. 각 시점마다 새로운 샘플 데이터가 기존 신경망에 들어가고, 이 결괏값이 TinyOL로 입력된다. 여기서 작업에 따라 누적된 평균과 분산이 업데이트 되며 TinyOL의 입력값은 정규화 될 수 있다. 레이블이 이용 가능할 경우 평가 메트릭과 추가 레이어의 가중치는 SGD같은 온라인 경사 하강법에 의해 적응된다.
신경망이 업데이트 될 때 입력 샘플 페어는 효과적으로 제거된다. 오직 하나의 데이터 페어만이 스트리밍시 메모리에 있기 대문에 과거 데이터를 저장할 필요가 없다. 배치/오프라인 학습과 비교해서 TinyOL은 메모리를 적게 사용하고 수많은 스트리밍 데이터를 학습할 수 있다.

TinyOL 평가
평가 모델 구조
오토인코더를 supervised와 unsupervised 방식으로 구성하여 평가한다.
비지도 학습시엔 인력 데이터 X를 중간 임베딩 Z로 압축한 다음 X’으로 재구성한다. 여기서 loss는 MSE를 사용한다. 이는 이상치 탐지에 활용되고, 관측치가 학습 데이터와 너무 다르다면 오차가 훨씬 클 것이다. 이를 통해 정상/비정상을 구분할 수 있다.

실험은 모델을 파인튜닝하는 것과 다중 클래스로 학습하는 것 두 가지 컨셉으로 진행된다.
1. Fine-Tune
실생활에서 학습 데이터와 현장 데이터가 서로 맞지 않는 경우가 있다. 각 현장은 각자의 고유한 특성을 가지고 있다. 이로 인해 발생하는 concept drift는 모델 성능을 떨어뜨린다. 이를 해결하기 위해 현장 데이터를 오토인코더의 마지막 레이어를 TinyOL로 대체하여 파인튜닝한다. 여기서 온라인 학습은 손실을 누적하여 업데이트하는 것이 아닌 하나의 샘플에 대해서 계산한다.
2. Multi-Anomaly Classification
이는 이상치의 카테고리 디테일을 얻는다. 이를 위해 재구성 에러와 인코딩의 임베딩 Z를 이용한다. Z는 보통 입력 차원보다 작으며 중요한 특징을 포착하고 데이터 차원을 줄여준다. 인코더의 출력과 재구성 에러를 실행 분산과 평균으로 스케일링 해 준 다음 TinyOL 시스템에 입력 특징으로 넘겨준다.
서로 다른 이상치 패턴은 분류되어야 하고 TinyOL 시스템은 다중 클래스 분류 레이어로 초기화 되어있다고 가정한다. 각 클래스의 가중치 벡터는 유지되고 새로운 클래스가 들어오면 추가 뉴련을 자동으로 초기화한다.
환경
64MHz CPU와 256KB SRAM이 달린 아두이노 나노 33 BLE 보드와 USB 팬으로 실험을 진행하였다. 그리고 임베디드 센서는 x, y, z 3 개의 축으로 된 가속도 센서를 이용하였다.

보드는 USB 팬이 평상시에 있을 때, 끼여있을 때(stuck), 꺾였을 때(tilted)의 환경을 읽는다. 아래 그림은 각 환경에서 3개의 축의 진동 데이터이다.

Fine-Tune
다음의 이미지를 보면 학습 데이터와 현장 데이터의 차이를 볼 수 있다. 논문에서 말하길 학습시 환경과 최대한 유사하게 하여도 측정치의 차이는 어쩔 수 없이 생겼다고 한다.

이렇게 차이가 생기면 MSE에 임계값을 주어 이상치를 탐지해도 잘 작동하지 않을 것이다. 그렇기 때문에 파인튜닝을 해야 한다. 아래 그림에서 TinyOL은 이를 잘 수행함을 볼 수 있다.

다음 테이블에서 incremental 학습을 하는 동안 시간을 약간 더 소모하는 것을 볼 수 있다. 그러나 사후 학습(post-training)을 계속 하는 것이 아니고 정확도를 충족하면 하지 않기 때문에 큰 연산 지연 없이 각 모델에 대해 좋은 성능을 보장할 수 있다.

Multi-Anomaly Classification
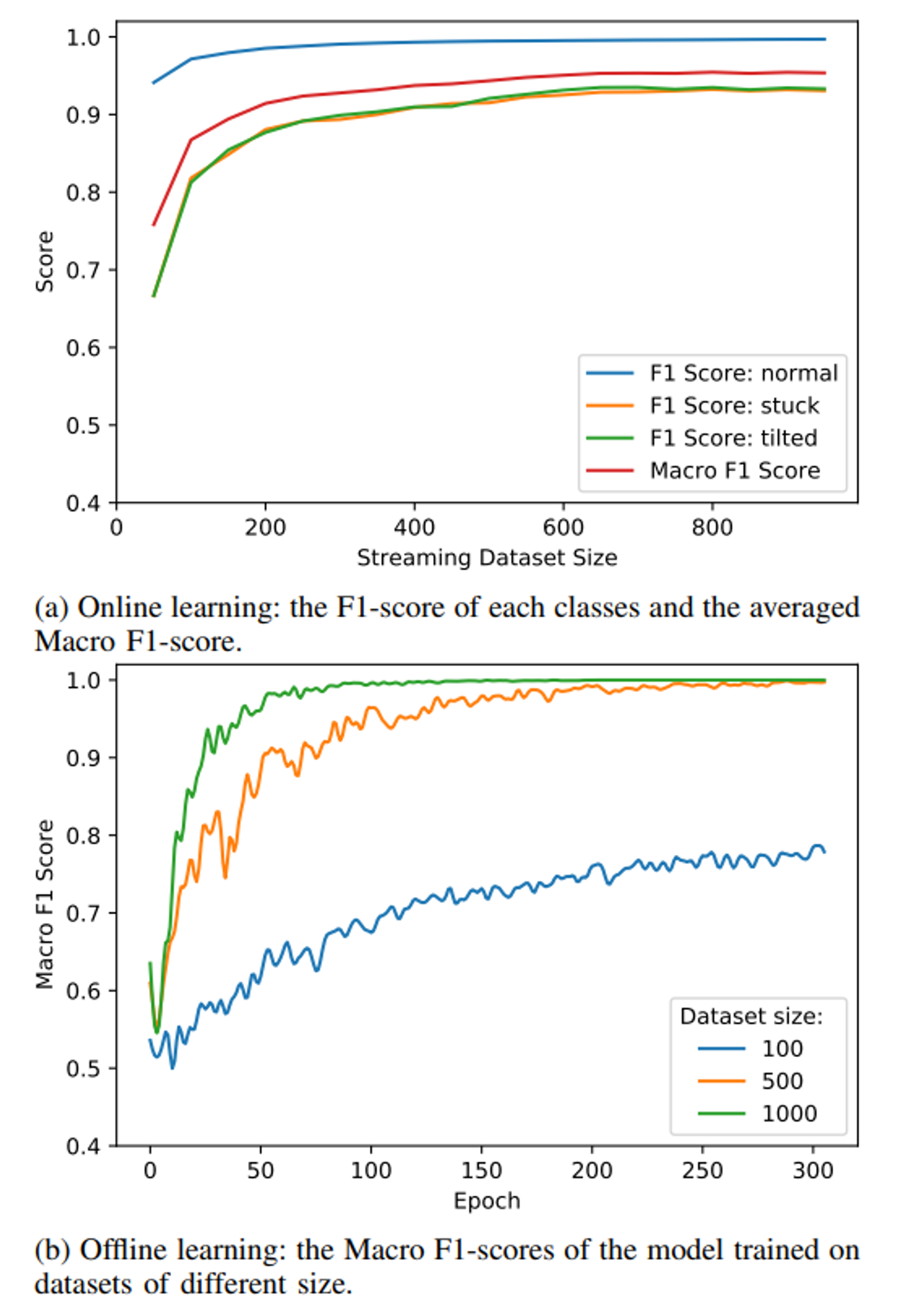
인코더의 출력과 재구성 에러 값을 입력 특징으로 활용해 normal, stuck, tilted를 분류한다. 팬을 각 모드로 놓고 블루투스를 통해 클래스 패턴을 학습하도록 했다.
온라인 학습은 50스텝마다 평가하였고 F1-score가 normal의 경우 다른 두 클래스보다 항상 높은 점수를 기록했는데, 저자들은 이를 오토인코더가 normal만 학습하였기 때문일 것이라고 추측했다. 인코더의 가중치가 고정되어 있기 때문에 이상치의 경우 효과적으로 특징을 추출하지 못했을 것이라 한다.
오프라인 학습과의 비교시 결과는 데이터 수가 충분하고 50에폭 이상 학습한 경우에는 오프라인 학습이 더욱 높은 성능을 보였다. 그러나 이는 더 많은 컴퓨팅 자원을 필요로 하기 때문에 온라인 학습도 충분한 경쟁력을 갖는다고 한다.
'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| [논문 리뷰]DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING (2) | 2023.11.11 |
|---|---|
| [논문 리뷰]TinyTL: Reduce Activations, Not Trainable Parameters for Efficient On-Device Learning (0) | 2023.11.08 |
| SetFit 조사 및 distilbert와 sentiment analysis 성능 비교 (1) | 2023.08.19 |
| llama2 다운 및 파인튜닝 (7) | 2023.08.07 |
| LLM 조사 (0) | 2023.08.07 |