
티스토리 뷰
[RecSys] Modern Recommendation Systems with Neural Networks
ProWiseman 2023. 4. 12. 02:01들어가며
본 글은 Modern Recommendation Systems with Neural Networks을 번역 및 재구성 한 글입니다.
추천 시스템
추천 시스템은 여러 제품에 대한 사용자의 선호도를 예측하는 모델이다. 가장 일반적인 방법은 제품 피처 (Content-Based), 유저 유사도 (Collaborative Filtering), 개인 정보 (Knowledge-Based)를 활용하는 것이다. 신경망의 인기가 높아지며 이 요소를 모두 통합하는 하이브리드 추천 시스템에 대한 실험이 이루어지고 있다.
Cold Start
넷플릭스와 같은 서비스에 유저가 처음 가입하면 활동이 기록된게 없기 때문에 유저의 이전 상호작용 없이 추천해 주어야 한다. 이렇게 유저나 제품이 새로 들어올 때 직면하는 문제를 Cold Start problem이라고 한다. 시스템이 충분한 데이터가 없어 유저와 제품 사이에 관계를 형성할 수 없는 문제이다.
이 문제를 해결하기 위한 주요 기술은 Knowledge-Based approch이다. 초기 프로필 작성을 위해 유저가 선호하는 것을 물어보거나 인구 통계학적 정보를 활용한다. ex) 아이들에겐 애니메이션이나 카툰을 추천해주거나 10대들에겐 고등학교물을 추천해주는 식
단, 여기서 활용할 데이터는 유저와 관련된 데이터가 없기에 활용되지 않는다. 대신 후술한 Context 정보를 활용한다.
본 글에선 전통적인 모델과 현대적인 추천 시스템을 Python과 Tensorflow로 짜볼 것이다. 데이터셋은 수백 명의 유저로 수천 개의 영화 평가를 매겨놓은 MovieLens 데이터셋을 이용할 것이다. 다만 추천시스템 기법에 더 집중하기 위해서 원글에 있는 데이터셋 가공 부분은 생략한다.
가공해 놓은 데이터셋은 여기서 다운받을 수 있다.
가공 된 데이터 설명
dtf_context
유저와 유저가 본 영화, 유저가 영화를 본 때가 낮인지, 주말인지에 대한 여부를 나타내는 데이터프레임이다. 낮과 주말인지에 대한 여부는 timestamp로부터 추출했다.

dtf_products
영화의 이름, 영화가 2000년 이전에 나온 영화인지, 그리고 각 장르에 속하는지에 대한 여부를 나타낸다.

dtf_users
열은 유저, 행은 영화의 ID를 나타내며 유저가 평가를 내린 영화에 대한 행렬이다. 평점은 1~5점 사이이며 데이터프레임에 저장된 데이터는 신경망에서 더 좋은 성능을 위해 Min-Max Scaler로 전처리한 데이터이다.

코드 실습 전에 데이터를 로드한다.
import pandas as pd
import os
dtf_context = pd.read_csv(os.path.join(data_path, 'dtf_context.csv'))
dtf_products = pd.read_csv(os.path.join(data_path, 'dtf_products.csv'))
dtf_users = pd.read_csv(os.path.join(data_path, 'dtf_users.csv'))
dtf_users는 평가를 위해 train과 test 셋으로 나누어준다. (8:2)
split = int(0.8*dtf_users.shape[1])
dtf_train = dtf_users.iloc[:, :split-1]
dtf_test = dtf_users.iloc[:, split:]나눈 건 아래와 같은 식

Content-Based
Content-Based method는 제품 콘텐츠에 기반한다. 예를 들어 유저 A제 제품 1을 좋아하고, 제품 2가 제품 1과 유사하면 유저 A는 제품 2 또한 좋아할 것이라는 식이다.
이 아이디어는 유저가 평가를 내릴 때 제품 자체에 대한 평가를 내리는게 아닌 실제론 제품의 특징에 평가를 내린다는 것이다. 만약 유저가 음악과 예술에 관련된 제품을 좋아한다면 음악과 예술이라는 특징을 좋아한다는 것이다. 이에 기반해 같은 특징을 지니는 다른 제품을 유저가 얼마나 좋아할지 측정할 수 있다. 이러한 방법은 제품에 대한 정보는 알지만 유저에 대해는 모를 때 적합하다.

서비스에 충분한 제품 데이터가 있고 첫 번째 구독자가 들어온다 가정하며 한 명의 유저를 뽑고 이를 통해 학습, 테스트 벡터를 만든다.
import numpy as np
i = 1 # user ID
train = dtf_train.iloc[i].to_frame(name="y")
test = dtf_test.iloc[i].to_frame(name="y")
# 학습 셋과 테스트 셋의 Product를 모두 합치지만 테스트 셋의 y값은 숨김
tmp = test.copy()
tmp["y"] = np.nan
train = train.append(tmp)
모든 값이 NaN 같지만 y값을 포함하고 있다. (train에는 학습 셋의 y값만 있음)

이제 유저의 각 피쳐에 대한 가중치에 대해 예측해야 한다. 이는 User-Products 벡터와 Products-Features 행렬을 곱하여 유저가 각 피쳐에 주는 가중치에 대한 추정을 포함하는 User-Features 벡터를 얻는다. 이 가중치는 평점에 대한 예측을 얻기 위해 Products-Features 행렬에 다시 곱해진다.
## usr_ft(users,fatures) = usr(users,products) x prd(products,features)
usr_ft = np.dot(usr, prd)
## normalize
weights = usr_ft / usr_ft.sum()
## predicted rating(users,products) = weights(users,fatures) x prd.T(features,products)
pred = np.dot(weights, prd.T)
test = test.merge(pd.DataFrame(pred[0], columns=["yhat"]), how="left", left_index=True, right_index=True).reset_index()
test = test[~test["y"].isna()]
test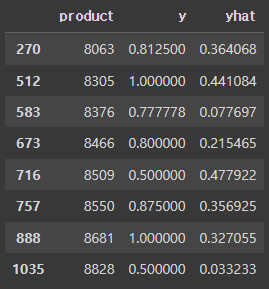
tensorflow로 진행하면 다음과 같다.
import tensorflow as tf
# usr_ft(users,fatures) = usr(users,products) x prd(products,features)
usr_ft = tf.matmul(usr, prd)
# normalize
weights = usr_ft / tf.reduce_sum(usr_ft, axis=1, keepdims=True)
# rating(users,products) = weights(users,fatures) x prd.T(features,products)
pred = tf.matmul(weights, prd.T)여기서 예측된 추천에 대한 평가는 정확도와 Mean Reciprocal Rank(MRR)을 이용한다.
※ MRR이란 : 사용자가 몇 개의 컨텐츠에 관심이 있었는지, 각 관련 컨텐츠는 어느 위치에 있었는지를 고려하지 않는다. 오직, 가장 상위의 관련 컨텐츠의 위치만을 고려하여 점수를 계산함으로써 가장 관련있는 컨텐츠가 얼마나 상위에 올라가 있는지를 평가하는 지표이다. (참고)
def mean_reciprocal_rank(y_test, predicted):
score = []
for product in y_test:
mrr = 1 / (list(predicted).index(product) + 1) if product
in predicted else 0
score.append(mrr)
return np.mean(score)이 함수를 가지고 다음의 코드를 이용해 평가한다.
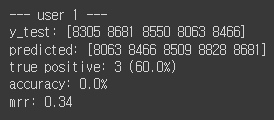
print("--- user", i, "---")
top = 5
y_test = test.sort_values("y", ascending=False)["product"].values[:top]
print("y_test:", y_test)
predicted = test.sort_values("yhat", ascending=False)["product"].values[:top]
print("predicted:", predicted)
true_positive = len(list(set(y_test) & set(predicted)))
print("true positive:", true_positive, "("+str(round(true_positive/top*100,1))+"%)")
print("accuracy:", str(round(metrics.accuracy_score(y_test,predicted)*100,1))+"%")
print("mrr:", mean_reciprocal_rank(y_test, predicted))
5개의 예측 중에 상품 4개는 맞췄지만 순서가 틀렸으므로 정확도와 MRR이 낮다.
세부 내용을 다음과 같은 코드로 살펴본다.
# See predictions details
test.merge(
dtf_products[["name","old","genres"]], left_on="product",
right_index=True
).sort_values("yhat", ascending=False)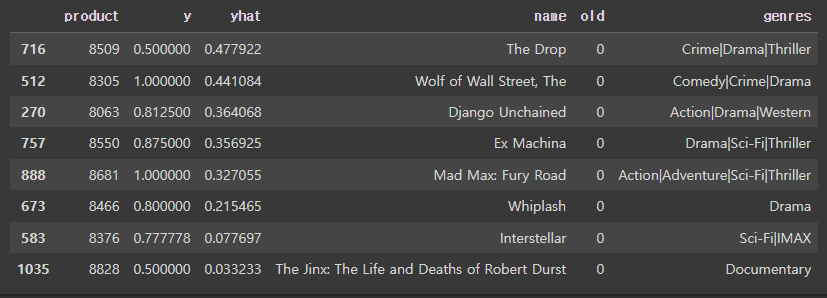
Collaborative Filtering
Collaborative Filtering은 비슷한 유저는 비슷한 제품을 좋아한다는 가정을 기반으로 한다. 만약 유저 A가 제품 1을 좋아하고, 유저 B는 유저 A와 유사하면 유저 B도 제품 1을 좋아할 것이라는 식이다. 두 유저는 비슷한 제품을 좋아하면 서로 비슷한 것이다.

이 방법은 제품에 대한 피처가 필요하지 않은 대신 많은 유저의 많은 평점이 필요하다.
Collaborative Filtering은 넷플릭스가 2009년 주최한 대회로부터 인기를 얻었으며 이 방법은 두 개로 분류될 수 있다.
Memory-based
코사인 유사도나 클러스터링과 같은 상관관계 지표로 유저의 유사도를 찾는 방법
Model-based
머신러닝의 지도학습과 dtf_users와 같은 Users-Products 행렬을 User 행렬과 Products 행렬 두 개의 더 작은 요소 표현으로 나누는 matrix factorization을 통해 특정 제품에 대해 유저가 어떻게 평점을 내릴지 예측하는 방법
이 방법은 surprise 라이브러리로도 할 수 있지만 더 정교한 Model-based approch를 위해 tensorflow/keras로 임베딩할 수 있다. 여기선 tensorflow/keras를 이용한다.
실습하기 앞서 다음의 코드로 필요한 데이터를 준비한다.
train = dtf_train.stack(dropna=True).reset_index().rename(columns={0:"y"})
test = dtf_test.stack(dropna=True).reset_index().rename(columns={0:"y"})
train.head()
이 모델의 주요 아이디어는 신경망의 임베딩 레이어로 \(Users\)와 \(Products\) 행렬을 만드는 것이다.
입력은 user-product 페어이고 출력은 평점으로 두어 학습 셋에는 없는 새로운 user-product 페어를 넣었을 때 모델이 \(Users\) 임베딩 공간의 user와 \(Products\) 공간의 product를 살펴본다. 따라서 이 방식은 총 사용자와 제품의 개수를 미리 지정해놔야 한다.
from tensorflow.keras import models, layers, utils
embeddings_size = 50
usr, prd = dtf_users.shape[0], dtf_users.shape[1]
# Users (1,embedding_size)
xusers_in = layers.Input(name="xusers_in", shape=(1,))
xusers_emb = layers.Embedding(name="xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
xusers = layers.Reshape(name='xusers', target_shape=(embeddings_size,))(xusers_emb)
# Products (1,embedding_size)
xproducts_in = layers.Input(name="xproducts_in", shape=(1,))
xproducts_emb = layers.Embedding(name="xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
xproducts = layers.Reshape(name='xproducts', target_shape=(embeddings_size,))(xproducts_emb)
# Product (1)
xx = layers.Dot(name='xx', normalize=True, axes=1)([xusers, xproducts])
# Predict ratings (1)
y_out = layers.Dense(name="y_out", units=1, activation='linear')(xx)
# Compile
model = models.Model(inputs=[xusers_in,xproducts_in], outputs=y_out, name="CollaborativeFiltering")
model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
문제는 손실함수를 MAE로 지정하여 회귀 문제로 정의하였다.
# Train
training = model.fit(x=[train["user"], train["product"]], y=train["y"], epochs=100, batch_size=128, shuffle=True, verbose=0, validation_split=0.3)
model = training.model
# Test
test["yhat"] = model.predict([test["user"], test["product"]])
test학습하고 예측하면 다음과 같은 결과가 나온다.
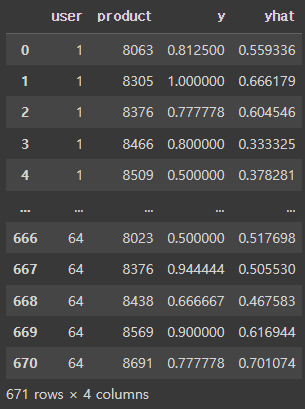

Neural Collaborative Filtering
현재 모든 SOTA 추천 시스템은 딥러닝을 활용한다. 특히 Neural Collaborative Filtering (2017)에선 신경망의 비선형성과 Matrix Factorization 결합했다. 여기서의 모델은 전통적은 Collaborative Filtering 뿐만 아니라 fully connected Deep Neural Network 또한 활용하여 임베딩 공간을 최대한 활용하도록 디자인 되었다. 추가된 신경망 부분은 Matrix Factorization이 놓칠 수도 있는 패턴과 특징을 포착한다.

모델 코드는 다음과 같다.
embeddings_size = 50
usr, prd = dtf_users.shape[0], dtf_users.shape[1]
# Input layer
xusers_in = layers.Input(name="xusers_in", shape=(1,))
xproducts_in = layers.Input(name="xproducts_in", shape=(1,))
# A) Matrix Factorization
## embeddings and reshape
cf_xusers_emb = layers.Embedding(name="cf_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
cf_xusers = layers.Reshape(name='cf_xusers', target_shape=(embeddings_size,))(cf_xusers_emb)
## embeddings and reshape
cf_xproducts_emb = layers.Embedding(name="cf_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
cf_xproducts = layers.Reshape(name='cf_xproducts', target_shape=(embeddings_size,))(cf_xproducts_emb)
## product
cf_xx = layers.Dot(name='cf_xx', normalize=True, axes=1)([cf_xusers, cf_xproducts])
# B) Neural Network
## embeddings and reshape
nn_xusers_emb = layers.Embedding(name="nn_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
nn_xusers = layers.Reshape(name='nn_xusers', target_shape=(embeddings_size,))(nn_xusers_emb)
## embeddings and reshape
nn_xproducts_emb = layers.Embedding(name="nn_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
nn_xproducts = layers.Reshape(name='nn_xproducts', target_shape=(embeddings_size,))(nn_xproducts_emb)
## concat and dense
nn_xx = layers.Concatenate()([nn_xusers, nn_xproducts])
nn_xx = layers.Dense(name="nn_xx", units=int(embeddings_size/2), activation='relu')(nn_xx)
# Merge A & B
y_out = layers.Concatenate()([cf_xx, nn_xx])
y_out = layers.Dense(name="y_out", units=1, activation='linear')(y_out)
# Compile
model = models.Model(inputs=[xusers_in,xproducts_in], outputs=y_out, name="Neural_CollaborativeFiltering")
model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
model.summary()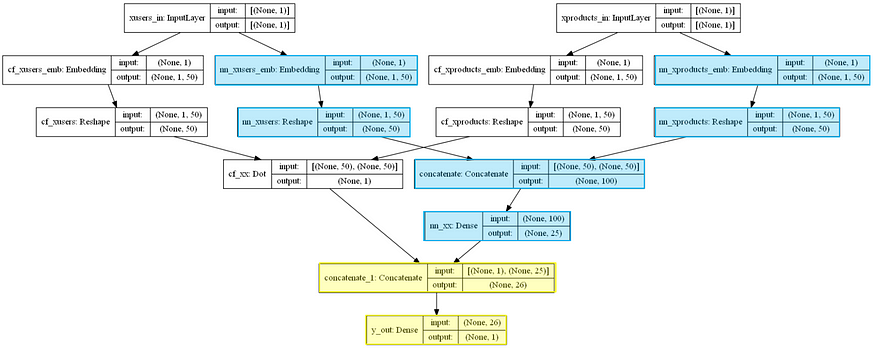
기존 협력 필터링과 크게 다르진 않지만 성능은 더 낫다고 한다. (내가 했을 땐 성능이 별로였다.)
# train
training = model.fit(x=[train["user"], train["product"]], y=train["y"],
epochs=100, batch_size=128, shuffle=True, verbose=0, validation_split=0.3)
model = training.model
# test
test["yhat"] = model.predict([test["user"], test["product"]])
test
Hybrid Model
현실 세계에서 제공하는 데이터의 종류는 다음과 같다.
Target variable
평점으로 이는 유저가 직접 피드백을 남기는 등 명시적일 수도, 혹은 유저가 영화 전체를 보면 긍정적인 피드백으로 가정하는 등 암시적일 수도 있다.
Product features
영화 장르와 같은 아이템에 대한 태그 / 설명이다. 대체로 Content-Based method에 활용된다.
User profile
유저에 대한 설명 정보로 성별과 나이같은 인구 통계학적 정보나 선호, 스크린에서의 평균 시간, 서비스를 가장 많이 사용하는 시간과 같은 행위 정보이다. 대체로 Knowledge-Based 추천에 활용된다.
Context
평점과 관련된 상황에 대한 추가 정보로 예시론 영화 시청 기록, 언제 봤는지, 어디서 봤는지와 같은 정보가 있다. 보통 Knowledge-Based 추천에 포함된다.
현대 추천 시스템은 이 정보를 모두 결합하여 예측을 한다. 유튜브의 경우 구글이 유저에 대해 알고있는 모든 정보를 활용하여 다음 동영상을 추천한다.
이 글의 예시에선 Product feature와 유저가 언제 평점을 매겼는지에 대한 Context가 있다. 여기서 Context는 User profile 대신 활용된다.
모델에 넣기 위해 product feature와 context를 생성한다.
features = dtf_products.drop(["genres","name"], axis=1).columns
print(features)
context = dtf_context.drop(["user","product"], axis=1).columns
print(context)train = dtf_train.stack(dropna=True).reset_index().rename(columns={0:"y"})
## add features
train = train.merge(dtf_products[features], how="left", left_on="product", right_index=True)
## add context
train = train.merge(dtf_context, how="left")
test = dtf_test.stack(dropna=True).reset_index().rename(columns={0:"y"})
## add features
test = test.merge(dtf_products.drop(["genres","name"], axis=1), how="left", left_on="product", right_index=True)
## add context
test = test.merge(dtf_context, how="left")
이제 context-aware hybrid model을 위한 재료를 모두 준비했다. 신경망의 유연성은 우리가 원하는 모듈을 추가할 수 있게 한다. 이를 이용해 Neural Collaborative Filtering 구조에 최대한 많은 모듈을 포함시킨다.

모델 코드는 다음과 같다.
embeddings_size = 50
usr, prd = dtf_users.shape[0], dtf_users.shape[1]
feat = len(features)
ctx = len(context)
################### COLLABORATIVE FILTERING ########################
# Input layer
xusers_in = layers.Input(name="xusers_in", shape=(1,))
xproducts_in = layers.Input(name="xproducts_in", shape=(1,))
# A) Matrix Factorization
## embeddings and reshape
cf_xusers_emb = layers.Embedding(name="cf_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
cf_xusers = layers.Reshape(name='cf_xusers', target_shape=(embeddings_size,))(cf_xusers_emb)
## embeddings and reshape
cf_xproducts_emb = layers.Embedding(name="cf_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
cf_xproducts = layers.Reshape(name='cf_xproducts', target_shape=(embeddings_size,))(cf_xproducts_emb)
## product
cf_xx = layers.Dot(name='cf_xx', normalize=True, axes=1)([cf_xusers, cf_xproducts])
# B) Neural Network
## embeddings and reshape
nn_xusers_emb = layers.Embedding(name="nn_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
nn_xusers = layers.Reshape(name='nn_xusers', target_shape=(embeddings_size,))(nn_xusers_emb)
## embeddings and reshape
nn_xproducts_emb = layers.Embedding(name="nn_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
nn_xproducts = layers.Reshape(name='nn_xproducts', target_shape=(embeddings_size,))(nn_xproducts_emb)
## concat and dense
nn_xx = layers.Concatenate()([nn_xusers, nn_xproducts])
nn_xx = layers.Dense(name="nn_xx", units=int(embeddings_size/2), activation='relu')(nn_xx)
######################### CONTENT BASED ############################
# Product Features
features_in = layers.Input(name="features_in", shape=(feat,))
features_x = layers.Dense(name="features_x", units=feat, activation='relu')(features_in)
######################## KNOWLEDGE BASED ###########################
# Context
contexts_in = layers.Input(name="contexts_in", shape=(ctx,))
context_x = layers.Dense(name="context_x", units=ctx, activation='relu')(contexts_in)
########################## OUTPUT ##################################
# Merge all
y_out = layers.Concatenate()([cf_xx, nn_xx, features_x, context_x])
y_out = layers.Dense(name="y_out", units=1, activation='linear')(y_out)
# Compile
model = models.Model(inputs=[xusers_in,xproducts_in, features_in, contexts_in], outputs=y_out, name="Hybrid_Model")
model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
새로운 입력값도 포함해서 학습시킨다.
# Train
training = model.fit(x=[train["user"], train["product"], train[features], train[context]], y=train["y"],
epochs=100, batch_size=128, shuffle=True, verbose=0, validation_split=0.3)
model = training.model
# Test
test["yhat"] = model.predict([test["user"], test["product"], test[features], test[context]])
test

다른 방법들에 비해 하이브리드 모델이 가장 높은 정확도를 보인다.
모델의 구조를 간단하게 표현하면 다음과 같다.

'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| 추천 시스템 (0) | 2023.05.15 |
|---|---|
| Text 분야에 적용된 Metric 기반 방법론 찾기 (0) | 2023.04.18 |
| [논문 리뷰]Few-shot learning for short text classification (0) | 2023.04.06 |
| 인공지능 기초 4 (1) | 2023.03.25 |
| 인공지능 기초 3 (0) | 2023.03.20 |