
티스토리 뷰
들어가며
본 글은 논문 Few-shot learning for short text classification을 리뷰한 글입니다.
기존 short text classification의 문제
few-shot learning 접근법은 비전 도메인에선 좋은 성취를 얻었지만 자연어 처리 / 분류, 특히 짧은 텍스트 분류에서는 상대적으로 아니다.
트위터와 같은 짧은 텍스트와 문장에선 제한된 문장 길이, 축약어, 오타, 잘못된 문법을 사용하는 자유분방한 문장 구성과 같은 특징이 있다.
보통 언어는 고차원 공간에 의미 공간(semantic space)이 있고 이 의미 특징(semantic feature)과 워드 임베딩은 많은 NLP 과업에 유익하다고 여겨지고 더 많은 라벨링으로 분류기의 성능을 개선할 수 있을 것 같지만 만족할 만한 분류기 성능을 만들기 위한 충분한 의미 정보를 얻기엔 수백만 개의 라벨링 된 샘플도 모자라다.
추정하기를 그 이유가 희소성(sparsity), 문장이 레이블에 대해 충분한 정보를 전달하거나 분포 특성 공간에서 서로 다른 문장을 분별하기엔 너무 짧기 때문이다.
논문에서의 이를 위한 해결법
분류기를 학습시키기 위해 충분한 샘플을 얻을 수 없기 때문에 short text classification에 few-shot learning을 도입한다.
Siamese CNN 아키텍쳐로 분별 있는 텍스트 인코딩을 학습한다.
prototype을 도입한다.
구체적인 방법은 Large margin nearest neighbor (LMNN) 분류와 CNN에서 영감을 받았다.
Deep network architecture
본 논문의 네트워크 아키텍쳐로 Siamese network를 채택했다.
Siamese network
파라미터를 공유하는 두 개의 동일한 하위 네트워크로 구성된 신경망 아키텍처이며 보통 준지도학습에 사용된다.
Siamese network는 파라미터를 공유하고 다른 입력값을 받지만 energy function layer로 결합된다. energy function layer는 최고 수준 특징 표현(highest-level feature representation)의 지표를 계산한다. (최고 수준 특징 표현은 특징 추출 부분 최 우측을 의미하는 것 같다.)
Single layer CNN
논문에서는 베이스 네트워크로 convolutional layer 한 개, max pooling layer, fully connected hidden layer로 구성된 single layer CNN 아키텍처를 이용한다. 과적합 방지를 위해 FC 레이어에 dropout도 추가한다.
CNN은 텍스트 행렬 쌍에 최적화되고 인력을 비선형 매핑으로 표현한다. 행렬은 저차원의 벡터로 다시 인코딩하기 위해 두 개의 동일한 CNN으로 전파하고 표준 거리 지표로서 \(L_{2}\) 놈을 계산한다.
이 과정의 목표는 추후 분류기 학습에 더 나은 전문화와 일반화를 위해 분별있는 특징을 학습하는 것이다.
loss function
loss function은 입력 \(x_{i}\)와 \(x_{j}\)가 있을 때 같은 레이블일 경우 거리 (\(x_{i}, x_{j}\))를 최소화하고 다른 레이블일 경우 거리 (\(x_{i}, x_{j}\))를 최대화하도록 디자인했다. 거리 지표로 \(L_{2}\) 놈을 사용하고 규제식으로 \(\textit{hinge}\) loss function을 사용했다.
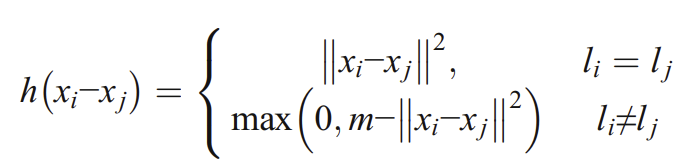
\(l_{i}\)는 CNN으로 다시 인코딩된 텍스트 벡터 \(x_{i}\)의 레이블이다. hinge loss는 같은 레이블의 벡터는 서로 가깝게, 다른 벡터는 서로 최소한 거리 \(m\)을 지니도록 하는 마진 기반 손실의 일종이다. 이 hinge loss는 고차원의 텍스트 데이터에선 많은 컴퓨팅 자원을 요하기 때문에 Rmsprop로 파라미터를 최적화한다.
twin networks
twin network의 아키텍처는 다음과 같다.
- 문장을 64 × 300 사이즈 행렬로 변환한다.
- 각 열은 하나의 단어 벡터를 의미한다.
- 문장의 길이를 64로 패딩한다.
- 필터의 너비는 단어 벡터의 너비와 같다.
- 이는 필터의 높이를 \(h\)라 할 때 convolution layer가 64 × 300 행렬 입력을 (64-\(h\) + 1) × 1의 피쳐맵 벡터로 변환한다는 의미이다.
- one convolution layer
- 100개의 필터와 3개의 채널을 가진다.
- 각 채널은 3 × 300, 4 × 300, 5 × 300의 서로 다른 필터 크기에 해당한다.
- 활성함수로 ReLU를 사용한다.
- max-polling layer로 피쳐맵 벡터를 하나의 최댓값으로 압축한다.
- fully connected layer로 모든 피쳐를 하나의 벡터로 집중시킨다.
- twin network의 두 벡터 간의 hinge loss로 분별 있는 표현을 학습한다.
- sigmoid로 출력을 [0, 1]로 만들어준다.
- 두 문장이 같은 클래스면 1, 다르면 0이다.

Network training
본 논문의 프레임워크에선 두 개의 학습 단계로 나뉜다. 첫 번째는 CNN 모델을 사전학습 시키는 것이고 두 번째는 앞선 사전학습된 CNN 모델로 Siamese CNN을 구성하고 few-shot learning strategy로 Siamese CNN을 파인튜닝하는 것이다.
Pre-train a CNN
CNN 모델을 학습시키기엔 시간이 오래 걸리므로 CNN 파라미터를 초기화하기 위해 사전학습을 진행한다. 사전학습된 CNN은 짧은 텍스트 행렬을 동일한 길이의 벡터로 변환한다.
사전학습을 시작할 때 문장은 토큰화(tokenize)와 워드 임베딩을 통해 단어 임베딩으로 변환해야 한다. 본 논문에선 워드 임베딩으로 word2vec을 사용하였다. 토큰화된 문장은 \(x_{i} \in \textit{R}^{k}\)는 \(k\) 차원의 단어 벡터일 때 \(\chi = <x_{1},x_{2}, \cdots , x_{i},\cdots , x_{n}>\)으로 표현될 수 있다. 또한 모든 문장은 길이 \(n\)으로 패딩 된다. 너비가 \(d\)인 슬라이드 윈도우(필터)는 서브셋 \(\chi [i:i+d-1]\)를 만들기 위해 \(\chi\)에 적용된다. 여기서 \(d\)는 단어 벡터의 온전한 정보를 유지하기 위해 단어 벡터의 길이로 설정한다.
\(W \in \textit{R}^{dk}\)를 필터 행렬이라 하면 피쳐맵은 다음과 같이 정의된다.

여기서 \(b\)는 bias를 의미하고 \(\circ\)은 합성곱 연산자를 의미한다. 함수 \(f(x)\)는 convolutional layer의 활성함수로 ReLU를 사용하였다. 필터가 문장 \(\chi\)의 각 슬라이드 윈도우에 적용될 때 문장 행렬은 다음과 같이 만들어진다.

그다음 가장 중요한 피쳐는 가장 높은 값이라는 아이디어 때문에 convolutional layer 이후에 max pooling 연산을 적용한다. Fully connected layer는 모든 피쳐를 벡터로 매핑하는데 집중한다. 이후 지도학습으로 역전파를 하기 위해 소프트맥스 층을 연결하였다.
데이터셋은 보통 불균형하고 소프트맥스 분류기는 모든 샘플을 주요 클래스로 식별하려는 경향이 있기 때문에 사전학습 단에선 소프트맥스 분류기를 최적화하기 위해 파인튜닝을 하지 않았다.
본 실험에선 배치 사이즈는 50, dropout은 0.5, 학습률은 0.95를 사용했다. convolution layer에 필터 100개와 100 × 3 × 300, 100 × 4 × 300, 100 × 5 × 300의 세 채널을 사용했다. 네트워크는 25 에폭 학습했다.
Few-shot learning
few-shot learning으로 에피소드 학습 전략을 취한다. 에피소드는 훈련 셋과 테스트 셋으로 구성되어 있으며 이 전략은 테스트 셋에 대한 신뢰도를 높이고 일반화 성능을 개선한다.
에피소드를 구성하는 직관적인 방법은 클래스별로 \(n\) 개의 서포트 샘플을 구성하는 것이다. 그러나 짧은 문장 분류에서의 상황은 이미지 도메인과는 달리 일반적으로 클래스의 수가 적다. 보통 positive, negative, neutral(논문에선 neural이라 적혀있었는데 문맥상, 그리고 레퍼런스를 살펴봤을 때 neutral이 맞는 것 같다.)로 나뉘고 각 클래스별로 수백 개의 서포트 샘플이 있다. 게다가 각 클래스별로 다양한 주제, 문맥, 문장 구조가 많이 있다.
본 실험에선 prototype이란 아이디어를 적용하였다. 클래스가 같던 다르던 문장의 주제와 구조가 다르면 다른 prototype에 있다고 보는 것이다. 게다가 소프트맥스 분류기가 식별하기를 실패한 샘플도 prototype 셋에 넣어준다. 그다음 stochastic sampling strategy에 기반해 prototype 샘플을 \(K\) 개의 샘플들로 조합한다.
데이터셋은 샘플 페어가 (\(x_{k}, x_{m}\))이고 \(d_{i}\)가 페어의 레이블일 때 \(\left\{\left [ \left ( x_{1}, x_{2} \right ), d_{1}, \right ], \cdots ,\left [ [\left ( x_{k}, x_{m} \right ), d_{i} \right ], \right\}\)로 표현될 수 있다. (\(x_{k}, x_{m}\))가 같은 클래스를 지니면 \(d_{i}\)는 1, 아니면 0(논문에선 1이라 돼 있는데 이 또한 문맥상 서로 레이블이 달라야 할 것 같다. 물론 제가 잘못 이해했을 수 있습니다.)이다. siamese network에 주어지는 데이터는 같은 클래스와 다른 클래스 페어의 비율이 1:1이어야 한다.
Siamese CNN을 few-shot learning으로 학습시킬 때, 소프트맥스 분류기 대신 cost sensitive SVM 분류기를 연결한다. 벤치마크 데이터셋이 불균형(im-balance) 하기 때문에 데스트 데이터를 더욱 정교하기 식별하기 위해 cost sensitive SVM 분류기를 학습시킨다.
※ cost sensitive learning은 클래스를 오분류했을 때 비용을 고려해 주는 것으로, 소수클래스의 비용함수(Cost function)에 높은 가중치를 부여하는 방식이라고 한다. 참고자료
실험
word2vec으로 GoogleNews-vectors-negative300-SLIM.bin을 학습한 것을 사용하였다고 한다.
Siamese CNN의 파라미터는 다음과 같다.
- 배치 사이즈 : 50
- dropout : 0.5
- learning rate : 0.95
- convolution layer : 100 filters, three channel 100 × 3 × 300, 100 × 4 × 300, 100 × 5 × 300
- 네트워크를 25 에폭만큼 학습시켰다.
- 페어 데이터는 세 파트로 나누었다.
- 최종 정확도는 세 학습 데이터셋의 평균 정확도로 취했다.
사용 데이터셋은 다음과 같다.
- Multigames data
- Hcr data
- SS-Tweet data
- Semeval_b data

Comparing with traditional methods
Adaboost, linear Support Vector Machine, Max Entropy, Random Forest, Naive Bayes Network와 같은 전통적인 방법론끼리도 비교했다. 불용어 제거, Sentiment WordNet(SentiWordNet), part-of-speech tagging(POS), 이모티콘, 유니그램으로 벤치마크 데이터셋에서 BOW(Bag Of Words) 피처를 추출했다.
※ 각 용어 설명
- 불용어 제거 : 'the', 'and', 'a'와 같은 텍스트 분석 시 중요하지 않은 단어를 제거하는 것
- SentiWordNet : 의미에 따라 단어에 감정 점수를 할당하는 어휘집
- POS : 텍스트 코퍼스에 명사, 동사, 형용사와 같은 단어 간 문법적 구조와 관계를 라벨링 하는 것
- 유니그램 : 학습말뭉치에 등장한 각 단어 빈도를 세어서 전체 단어수로 나누어준 것
데이터셋에서의 샘플 클래스 분포 불균형을 고려할 때 cost sensitive SVM이 linear SVM보다 더 적합할 것이다. 따라서 실행 시 cost-sensitive Linear SVM을 사용했다. 또한 랜덤 다운샘플링으로 모델 학습 시 불균형 정도를 완화했다.
아래 테이블을 봤을 때 RF와 Linear SVM이 다른 전통적인 분류기보다 나은 성능을 보이나 논문에서 제안된 Siamese CNN 접근법이 정확도면에서 모든 면을 능가한다고 한다.

Comparing with deep learning methods
Simple RNN, LSTM, DSC(오토인코더를 이용한 텍스트 분석 방법론)으로 본 논문의 접근법과 비교했다.
SRNN, LSTM 모두 분류기로 소프트맥스를 사용하였으며 피쳐로 워드 임베딩 대신 BoW를 이용했다고 한다. 둘 모두 훈련은 rmsprop 옵티마이저를, 활성함수로 tanh를 사용했고 dropout은 0.5, 은닉층 차원은 200을 사용했으며 10-15 에폭 이후 성능을 측정했다고 한다. 단순히 LSTM을 사용함으로써 SRNN보다 더 나은 성능을 얻는다. 그러나 SRNN, LSTM, DSC 모두 Siamese-CNN을 능가하진 못했다.
이런 방법론들이 더 낮은 성능을 보이는 주요 이유는 데이터의 불균형이다. 실현 가능한 솔루션으로 다른 클래스 샘플의 분포를 맞춰주는 것이나 라벨링 된 샘플이 많이 필요하므로 비싼 코스트로 인해 대부분 적용 불가능하다.
위에서 살펴본 데이터 짝을 지어주는 방법은 불균형의 부정적인 영향을 제거하는데 도움이 된다.
또한 word2vec은 CNN이 더 귀중한 정보를 얻도록 돕는다. BoW 벡터는 보통 고차원에 sparse하다. 따라서 분류기가 학습 샘플을 엄청나게 요하게 된다. word2vec은 분류기에 dense 하고 연속인 벡터 공간을 제공할 수 있다. 따라서 워드 임베딩 벡터 공간이 더 나은 성능을 얻는다.

'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| Text 분야에 적용된 Metric 기반 방법론 찾기 (0) | 2023.04.18 |
|---|---|
| [RecSys] Modern Recommendation Systems with Neural Networks (0) | 2023.04.12 |
| 인공지능 기초 4 (1) | 2023.03.25 |
| 인공지능 기초 3 (0) | 2023.03.20 |
| 인공지능 기초 2 (0) | 2023.03.13 |