
티스토리 뷰
들어가며
본 글은 Deep contextualized word representations을 리뷰한 글입니다.
내용
몰랐던 용어 정리
Monolingual corpus
단일 언어 말뭉치
Parallel corpus, multilingual corpus
두 개 이상의 monolingual corora. 말뭉치는 서로 번역본이다. 자료 출처
기존 연구의 한계
사전학습된 word vector는 거대한 규모의 레이블이 되지 않은 텍스트에서 구문(syntactic)과 의미(semantic) 정보를 포착하는데 탁월했기에 question answering, textual entatilment, semantic role labeling과 같은 SOTA NLP 아키텍처에서 표준 구성으로 쓰였다. 그러나 word vector를 학습하기 위한 이런 접근방식은 각 단어에 대해 문맥에 독립된 단일의 표현만 배울 수 있다.
Ex) Bank라는 단어는 은행과 강둑이란 전혀 다른 의미를 가지나 Word2Vec이나 GloVe 등으로 표현된 이베딩 벡터들은 이를 제대로 반영하지 못한다. 자료 출처
논문에서의 키 아이디어
- character convolution을 이용해 하위 단어(subword)의 이점을 취한다.
- 미리 정의된 의미(sense) 클래스를 예측하도록 명시적으로 학습하지 않고 다중 의미 정보(multi-sense information)를 downstream task로 매끄럽게 통합한다.
- 문맥에 의존적인 표현을 학습하기 위해 Bi-LSTM으로 pivot word 근처의 문맥을 인코딩하거나 pivot word를 표현 자체에 포함시키고 supervised NMT(neural machine translation)나 unsupervised LM(language model)으로 학습시킨다.
- 이런 접근 방식은 대규모 데이터셋에서 효과적이다.
- 본 논문에선 크기가 제한적인 parallel corpora 대신 monolingual 데이터로 학습하여 위 이점을 취한다. (약 3천만 문장)
ELMo: Embeddings from Language Models
고퀄리티의 단어 표현은 이상적으로 구문(syntax)과 의미(semantics)와 같은 단어의 쓰임의 복잡한 특성과 이러한 쓰임이 다의어 모델링과 같이 언어의 맥락에 따라 어떻게 다른지 모두 모델링해야 하므로 어렵다. ELMo의 deep contextualized word representation은 이 두 가지를 모두 직접적으로 다룬다.
ELMo의 단어 표현은 입련 문장 천제에 대한 함수이다. 이 함수는 내부 네트워크 상태의 선형 함수로 character convolution으로 구성된 2계층 biLM으로 연산한다. 이런 셋업은 biLM이 대규모로 사전 학습되는 준지도 학습을 할 수 있게 하고 현존하는 신명망 NLP 아키텍처에 폭넓게 포함시킬 수 있도록 한다.

Bidirectional language models
이 파트에선 biLM의 구성에 대해 알아볼 것이다.
최신 SOTA neural LM은 문자에 대해 토근 임베딩이나 CNN을 통해 문맥에 대해 독립적인 토큰 표현
역방향 언어 모델은 시퀀스가 거꾸로인 것만 제외하면 순방향 언어 모델과 유사하다. 이전 토큰을 미래 문맥으로 예측하는데 이의 식은 다음과 같다.
순방향에서와 비슷하게 각 역방향 LSTM 층은
biLM은 앞서 본 순방향과 역방향 LM을 합친다. 논문에서의 수식은 순방향과 역방향 모두의 log likelihood를 최대화하며 식은 다음과 같다.
토큰 표현의 매개변수
ELMo
이 파트에선 biLM 레이어의 선형 조합인 단어 표현을 학습하기 위한 새로운 접근 방식에 대해 알아볼 것이다.
ELMo는 biLM의 중간층 표현의 태스크별 조합이다. 각 토큰
ELMo는 다운스트림 모델에 적용시키기 위해
여기서
결과
ELMo를 활용하면 모두 성능이 개선되는 것을 확인할 수 있다.
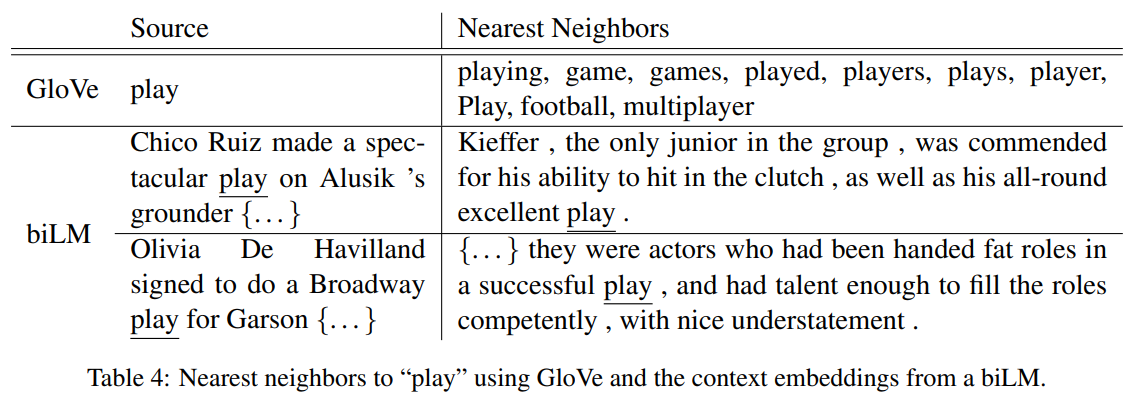
GloVe는 스포츠로써의 play에만 집중하는 반면 biLM은 소스 문장의 문맥 표현을 잘 캐치하고 있다.
'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| [논문 리뷰]EfficientNetV2: Smaller Models and Faster Training (0) | 2023.01.19 |
|---|---|
| [논문 리뷰]Sequence to Sequence Learning with Neural Networks (0) | 2023.01.19 |
| [TinyML]Tiny Machine Learning: The Next AI Revolution (0) | 2023.01.14 |
| StyleGAN / StyleGAN2 (2) | 2020.08.08 |
| CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms (3) | 2020.08.08 |