
티스토리 뷰
들어가며
StyleGAN과 StyleGAN2의 논문을 살짝 읽어보긴 했는데, 수식이 너무 어려워서 곤란해하던 중 From GAN basic to StyleGAN2 이란 포스트에 잘 정리돼 있어 위 포스트를 보고 공부하였다. 그래서 아래 정리한 내용들도 From GAN basic to StyleGAN2를 해석해 놓은 것이다. 하지만 이 포스트를 읽는 사람들은 GAN에 대해 알고 있다고 가정하고 GAN에 대한 내용은 대부분 생략했다.
내용
GAN evaluation metrics
GAN은 비지도 학습이기 때문에 지도 학습의 정확도나 F1 score와 같이 확립된 평가 방법(metric)이 없다. 여기에서는 StyleGAN이 제안한 자주 쓰이는 평가 방법인 Frechet Inception Distance와 Perceptual Path Length을 소개한다.
Frechat Inception Distance
Frechet Inception Distance(FID)는 생성된 이미지의 분포가 원본 이미지의 분포에 얼마나 가까운지 측정한다. 그러나 이미지는 고차원 공간에 매장되어 있기(embedded) 때문에 분포의 거리를 쉽게 측정할 수 없다. 그러므로 FID의 기본 개념은 최근 개발된 사람의 정확도를 뛰어넘는 이미지 인식 모델을 사용하여 저 차원 공간에 이미지를 매장(embedded)하고 그 공간에서 분포의 거리를 측정하는 것이다.
공식의 정의는 다음과 같으며 Wasserstein-2 거리는 Inception V3라고 불리는 네트워크에 의해 저차원 임베디드 벡터에 의해 계산된다. m과 c는 임베디드 공간의 평균 벡터(mean vectors)와 공변량 행렬(covariance matrices)이다. 아래 첨자로 w가 있는 기호는 생성된 이미지이고, 아래 첨자가 없는 것은 실제 이미지이다. 이것이 분포의 거리를 보여주기 때문에 값이 작을수록 가짜 이미지가 진짜 이미지처럼 보인다. 이것은 생성자가 더 나은 성능을 보여준다는 것을 가리킨다.

Perceptual Path Length
Perceptual Path Length(PPL)은 이미지가 "지각적(perceptual)"으로 부드럽게 바뀌었는지 나타내는 지표이다. FID와 유사하게 학습된 모델의 매장(embedded)된 이미지의 거리를 이용한다. 대략적으로 이것은 가짜 이미지의 시드(seed of fake images)의 잠재 공간이 가장 짧은 "지각적(perceptual)" 경로로 바뀌는지 가리킵니다. 이 개념은 다음 그림에 나와있습니다.
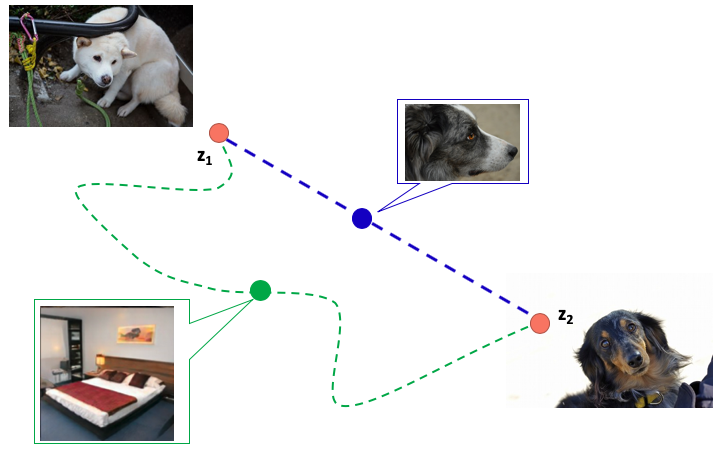
우리가 하얀 개를 생산하는 잠재 변수인 z1과 검정 개를 생산하는 잠재 변수 z2가 있다고 생각해 보자. 색깔 이외의 다른 요소는 바뀌지 않았으므로 중간의 데이터의 잠재 변수는 흰색과 검은색 사이의 경로에 따라 바뀌는 게 이상적이다. 즉 회색 개가 나오는 게 목표라고 할 수 있다. 다시 말해 색만 바뀌는 파란색 경로는 "지각적으로(perceptually)" 가장 짧은 거리이다. 반대로 객체의 모양을 바꾸고 침대와 같은 이미지를 통과하는 초록색 경로는 "지각적으로(perceptually)" 거리가 멀다.
이는 PPL로 정량화됐고 공식의 정의는 다음과 같다. 이것은 두 잠재 변수 z_1과 z_2를 비 t로 혼합해서(mixed) 얻어진 잠재 변수와 이 둘을 t + ε의 비율로 혼합해서(mixed) 얻은 잠재 변수에 의해 생성된 이미지 사이 거리의 기댓값이다.

아래 그림에서 보이는 것처럼 t와 t + ε로 혼합(mixed)된 데이터가 "지각적(perceptual)"으로 가까우면, 작은 값을 사용한다.

이는 t 주변의 잠재 변수를 이용하여 변화량 ε1과 ε2를 더하여 이미지를 생성하는 예이다. 파란색 길은 더 짧은 "지각적(perceptual)" 거리를 갖고 있다. 왜냐하면 우리는 t와 t + ε2의 회색 개가 더 유사하다고 생각하기 때문이다. 반면, 초록색 길에선, 침실이 나오는 이미지는 회색 개와 침실 사이에서 차이를 느끼기 때문에 "지각적(perceptual)" 거리가 크다. FID와 유사하게 우리는 VGG로 불리는 네트워크로 훈련된 매장된(embedded) 이미지의 거리를 사용한다. 이는 분석적으로 결정될 수 없기 때문에 많은 이미지에서 이 연산을 수행하고 예상 값을 얻은 결과는 PPL 값이다. 이 값이 작을수록, 잠재 공간이 지각적으로(perceptually) 더 부드러운 것이다.
StyleGAN
StyleGAN 네트워크는 두 가지 특징이 있다.
-
고해상도 이미지를 Progressive Growing을 통해 생성한다.
-
AdaIN을 통해 각 레이어에 이미지와 스타일을 결합한다.
첫 번째로 이 두 가지 특징과 StyleGAN의 세부적 구조에 대해 알아보도록 하겠다.

Progressive Growing
Progressive Growing은 Progressive-Growing(PG-GAN)에서 제안된 고해상도 이미지를 생성하는 방법이다. 대략 말하면 이는 저해상도의 이미지부터 시작해 점진적으로 고해상도 생성자(Generators)와 판별자(Discriminators)를 추가하여 고해상도 이미지를 만드는 방법이다.

위 그림에서, 이미지 생성을 4x4 해상도로 시작하여 점진적으로 해상도를 높이고 마지막으로 1024x1024의 고해상도 이미지를 생성한다. 네트워크가 해상도를 늘리기 위해 추가되더라도, 해상도를 위한 D와 G는 계속 학습한다.
AdaIN
AdaIN은 2017년 Xun Huang 외에 의해 제안된 style transfer의 정규화(normalization) 방법이다. 수학식은 아래와 같다. 이는 content input인 x와 style input인 y를 평균과 분산으로 정규화한다.


AdaIN은 Instance Normalization과 같은 다른 정규화(normalization) 방법과는 달리 오직 스타일과 콘텐츠 이미지의 통계로만 수행된다. 그리고 학습되는 파라미터는 쓰이지 않는다. 이는 학습 데이터에서 한 번도 본 적 없는 스타일로 변환할 수 있도록 한다.
AdaIN은 StyleGAN에선 다음과 같은 수식이 사용된다. 정규화된 콘텐츠 정보에 스타일을 사용해 선형 변환(linear transformation)에 적용한다는 컨셉은 변하지 않았다. 하지만 스타일의 표준 편차와 평균값 대신 후술 되는 스타일 벡터인 W에 선형 변환(linear transformation)인 y_s와 y_b가 사용된다.

Network architecture of StyleGAN
StyleGAN의 키포인트는 다음과 같다.
- 점진적으로 해상도를 올리기 위해서 Progressive Growing을 사용한다.
- 일반적인 GANs에서처럼 확률적(stochastically)으로 생성된 잠재 변수를 통해 이미지를 생성하는 것이 아닌 고정된 값의 텐서(fixed value tensor)를 통해 이미지를 생성한다.
- 확률적(stochastically)으로 생성된 잠재 변수는 8-layer의 비선형 변환 신경망을 통과한 후 각 해상도에 AdaIN을 통해 스타일 벡터로 사용한다.

위 그림의 (a)는 PG-GAN이고 (b)는 StyleGAN이다. 둘 다 점진적으로 해상도를 올리는 progressive growing을 사용한다. 그러나 PG-GAN은 확률적 잠재 변수 z로부터 이미지를 생성하는 반면, StyleGAN은 고정된 4x4x512 텐서로부터 이미지를 생성한다.
게다가 확률적 잠재 변수는 그대로 쓰이지 않고 스타일로서 쓰이기 전, Mapping Network라 불리는 fully connected network로 비선형 변환을 해 준다.
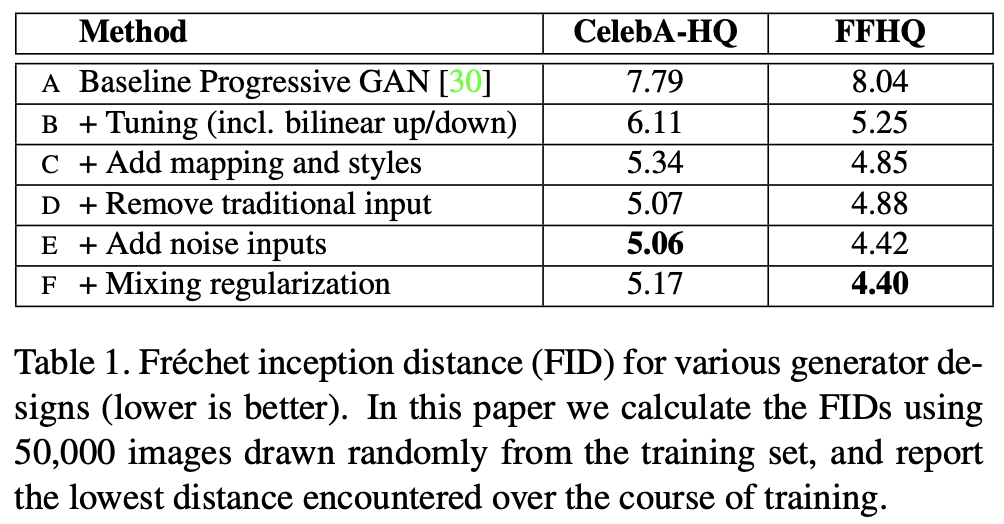
FID 점수는 고정된 값 텐서(fixed value tensor)로 이미지를 생성, Mapping network에 의한 스타일 도입 그리고 후술 할 혼합 정규화(mixing regularization)에 의해 개선되었다.
Mixing Regularization
StyleGAN은 Mixing Regularization이라 불리는 정규화(regularization) 방법을 사용하는 데, 이는 스타일에 사용된 두 잠재 변수를 학습하는 동안 혼합(mixes)하는 것이다. 예를 들어 스타일 벡터인 w_1과 w_2가 잠재 변수인 z_1과 z_2에서부터 맵핑(mapped)되었다고 할 , w_1은 4x4의 이미지를 생성할 때 사용되고 w_2는 8x8의 이미지를 생성할 때 사용된다.
이를 함으로써 아래 보이는 것과 같이 두 이미지의 스타일을 섞을 수 있다.

위 이미지에서 보이는 것과 같이, Source A와 Source B를 생성하는 잠재 변수가 사용되고 결과는 처음에 A의 잠재 변수를 사용하여 실험하고 특정 해상도에서 B의 잠재 변수를 사용하여 얻은 결과이다. 논문에선 스타일 B에 세 가지 해상도를 넣어 실험했다: 저해상도 (4²-8²), 중간 해상도 (16²-32²), 고해상도(64²–1024²) 기본적으로 저해상도에서 입력한 스타일의 영향이 큰 경향이 있으며 저해상도의 잠재 변수 B를 사용하는 것은 얼굴의 모양, 피부색, 성별, 연령 등 을 만들 것이다. 그러나 고해상도에서는 오직 배경과 머리색에서만 영향을 미쳤다.
Analysis of StyleGAN
우리가 봤다시피 StyleGAN은 아름다운 이미지를 생성할 수 있지만 이 모델은 약간의 노이즈와 부자연스러운 부분이 발생하는 것으로 알려져 있다.
처음으로, 아래 그림에서 보이는 물방울 같은 노이즈를 살펴보겠다.

이 노이즈는 생성된 이미지에서 항상 발생하진 않지만 해상도가 64x64의 모든 피쳐 맵에선 발생한다. 저자는 이 문제가 AdaIN으로 인해 발생한다고 말한다. 작은 spike-type distribution이 피쳐 맵으로 들어올 때, 원래 값이 작을지라도, 그 값은 정규화(normalization)에 의해 증가하고 큰 영향을 미칠 것이다. 실제로 정규화(normalization)를 제거하면 물방울이 사라지는 것처럼 보인다.
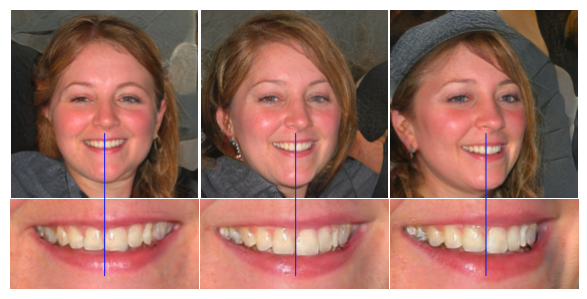
다음은 일부 피쳐들이 얼굴의 움직임을 따르지 않는 문제(mode)이다. 아래 이미지를 보면, 얼굴이 옆으로 변하지만, 이의 배열은 얼굴을 따르지 않아 부자연스럽게 만든다. 저자에 따르면 이 문제는 progressive growing으로 인해 발생한다고 한다. 각각의 해상도 이미지는 해당하는(corresponding) 생성자(Generator)에 의해 독립적으로 생성되기 때문에 이러한 특징이 자주 나타난다.
그런데, StyleGAN에 의해 소개된 Perceptual Path Length(PPL)의 분석은 이미지 품질과 연관이 있는 것으로 밝혀졌다. StyleGAN2의 저자는 고품질의 이미지를 생성하기 위해 생성자(Generator)가 고품질 이미지를 생성하기 위한 잠재 공간을 확장하는 것이 중요하고 저품질 이미지를 생성하기 위한 잠재 변수가 빠르게 변화하는 공간에 강제로 이동되기 때문이라고 말한다.

StyleGAN2에서는 PPL의 특성을 사용하여 이미지 품질을 개선하였고 물방울 노이즈와 따라오지 않는 문제를 개선했다. 이제 StyleGAN2가 문제를 어떻게 해결했고 이미지 품질을 개선했는지 살펴보겠다.
StyleGAN2
StyleGAN2의 요약과 주요 인사이트는 다음과 같다.
요약
StyleGAN의 개선. 물방울을 제거하기 위해 AdaIN 대신 CNN의 가중치를 정규화(normalization)하고 Progressive Growing을 제거하여 부자연스러운 문제(mode)를 개선하였으며 잠재 공간에 지속성(continuity)을 제공하여 이미지 품질을 향상했다. 이를 통해 FID 등 StyleGAN에 비해 굉장히 많이 개선되었다.
Key Insights
- AdaIN 같은 실제 통계(actual statistics)로 정규화(normalization)하는 대신 추정 통계(estimated statistics)로 정규화(normalization)하여 물방울을 없앤다.
- Progressive Growing 대신 skip connection을 갖고 있는 계층(hierarchical) 생성자(Generator)를 사용하여 눈과 이의 침체(stagnation)를 줄었다.
- 이미지 품질을 PPL을 줄이고 잠재 공간을 매끄럽게 하여(smoothing) 개선하였다.
StyleGAN2's methods
이 파트에선 StyleGAN2가 실제로 어떻게 작동하는지 살펴볼 것이다.
Normalization method instad of AdaIN
AdaIN은 실제로 넣은 데이터의 통계를 사용하여 정규화(normalizes)하는데, 이는 물방울 문제(modes)를 일으킨다. 저자는 실제 데이터의 통계 보단 추정 통계(estimated statics)를 사용하여 합성곱(convolution) 가중치를 정규화(normalization)하여 물방울을 예방했다. 아래 그림은 스키메틱 다이어그램이다.
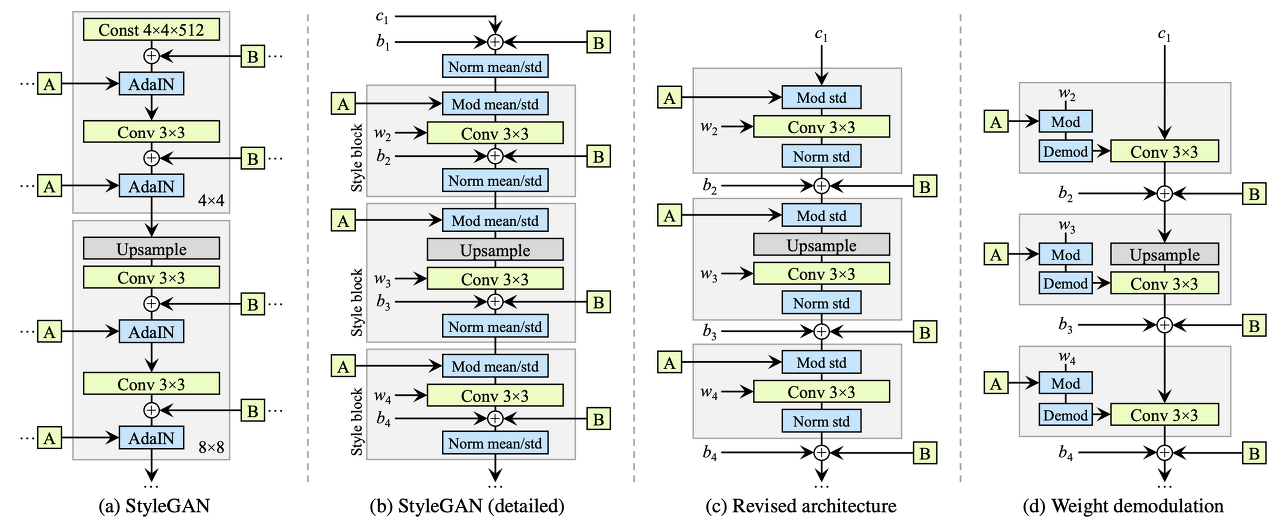
저자는 스타일 블록을 단순화하며 시작했다. (b의 갈색 영역)
AdaIN은 자세히 설명하면 두 단계로 나눌 수 있다. 첫 단계는 자체 통계로 콘텐츠 정보를 정규화(normalization)하는 것이다. 그리고 두 번째는 스타일 정보를 사용하여 정규화된 콘텐츠 정보의 선형 전이(linear transition)를 하는 것이다. StyleGAN (a)의 AdaIN부분이 이에 따라 확장되면 (b)와 같이 된다. AdaIN의 내부 작업은 다음과 같다. 콘텐츠의 정규화(normalization) -> 스타일 벡터에 의한 선형 변환(linear transformation). 스타일 블록에서의 순서는 다음과 같다. 스타일 벡터에 의한 선형 변환(linear transformation) -> (합성곱(Convolition) ->) -> 콘텐츠의 정규화(normalization).
다음으로, 저자는 평균값으로 작업하는 것은 불필요하다고 생각한다. 그래서 정규화(normalization) 작업을 표준 편차로만 나눈다. 그리고 또한 스타일의 선형 변환(linear transformation)을 계수를 곱하여 수행한다. 특히 노이즈 삽입 부분은 스타일 블록에서 이루어질 필요가 없기 때문에 스타일 블록에서 꺼냈다.(c)
스타일 블록의 내부 작업을 단순화했다. 이제 스타일 벡터에 의한 첫 번째 선형 변환(linear transformation)은 합성곱 연산(convoultion) 안에서 처리되어 수행된다. 스타일 블록에서, 스타일 벡터 W의 선형 변환(linear transformation)인 계수 y_s가 사용된다. 합성곱(convolution) 가중치 w_ijk와 함께 s를 곱한 콘텐츠 이미지를 처리하는 작업은콘텐츠 이미지를 가중치 w_ijk와 s의 곱과 합성곱 연산(convolving)하는 것과 같다. 그래서 이 작업은 다음과 같이 다시 쓰일 수 있다. ((d)의 Mod 연산이다.)

다음으로, 합성곱(convolution) 내부 처리에서 정규화(normalization) 작업(여기선 표준 편차로만 나뉜다.)을 수행하는 것을 고려하자. 여기에서 입력이 표준 정규분포와 출력의 표준 편차를 따르는 것으로 가정한다.
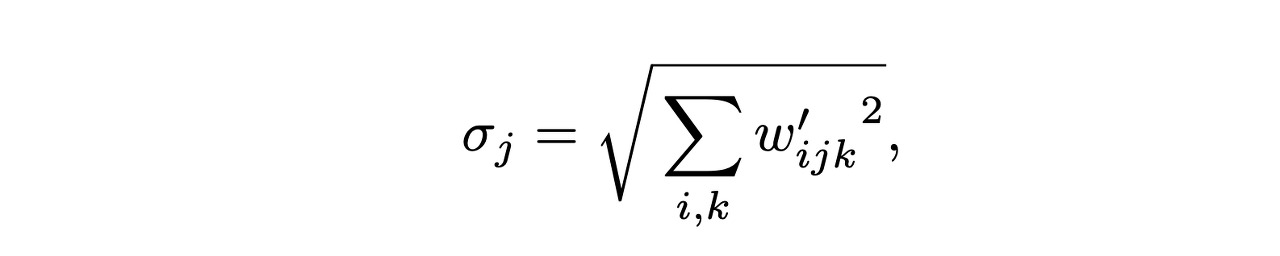
여기서 원하는 작업은 표준 편차의 역수로 출력을 곱하는 것이다. 가중치 w_ijk와 합성곱(convolution)의 곱셉에 표준 편차의 역수를 곱한 작업은 표준 편차의 역수에 곱한 가중치 w_ijk와 합성곱(convolution)하는 것과 같다. 따라서, 이 정규화(normalization) 작업은 다음과 같이 수행된다. ((d)의 Demod)

이에 의해, 스타일 블록의 작업 순서는 스타일에 의한 선형 변환(linear transformation) -> 합성곱(convolution) -> 출력 정규화(normalization)가 하나의 합성곱 과정(convolution process)으로 표현될 수 있다. 정규화(normalization) 부분은 출력이 정규 분포라 가정한 정규화(normalization) 과정이다. 다른 말로, 물방울을 발생시키는 실제 분포를 사용한 정규화(normalization)는 사용되지 않는다. 물방울은 이를 사용할 때 나오지 않는다.

A high-resolution image generation method instead of Progressive Growing
기존의 StyleGAN 생성자(Generator)는 단순한 구성을 갖고 있다. Progressive Growing 없이, 간단한 생성자(Generator)는 고해상도 이미지를 생성하기 어렵다. 그러나 생성자(Generator)와 판별자(Discriminator)의 표현 능력 증가로, 고해상도 이미지를 Progressive Growing 없이 생성할 수 있어 보인다.
Progressive Growing은 고해상도를 위해 생성자(Generator)와 판별자(Discriminator)를 점차적으로 추가하는 방법이고, 이는 고해상도의 이미지를 생성하기 위해 사용되는 방법 중 하나이다. 그러나 각 생성자(Generator)는 독립되어있기 때문에 이가 얼굴을 따라가지 않는 frequent features(어떻게 해석해야 할지 모르겠다.)를 생성하는 경향이 있다.
그러므로 저자는 Progressdive Growing을 사용하지 않는 고해상도 이미지 생성 방법을 제안했다. 네트워크는 MSG-GAN과 비슷하다. 아래 그림은 후보들이다.

최선의 네트워크를 선택하기 위해 논문에선 (b) 타입 생성자(Generator) / 판별자(Discriminator)와 (c) 타입 생성자(Generator) / 판별자(Discriminator)의 모든 조합을 실험하고 결과가 가장 좋은것을 선택했다. 다음의 테이블은 실험 결과이다.
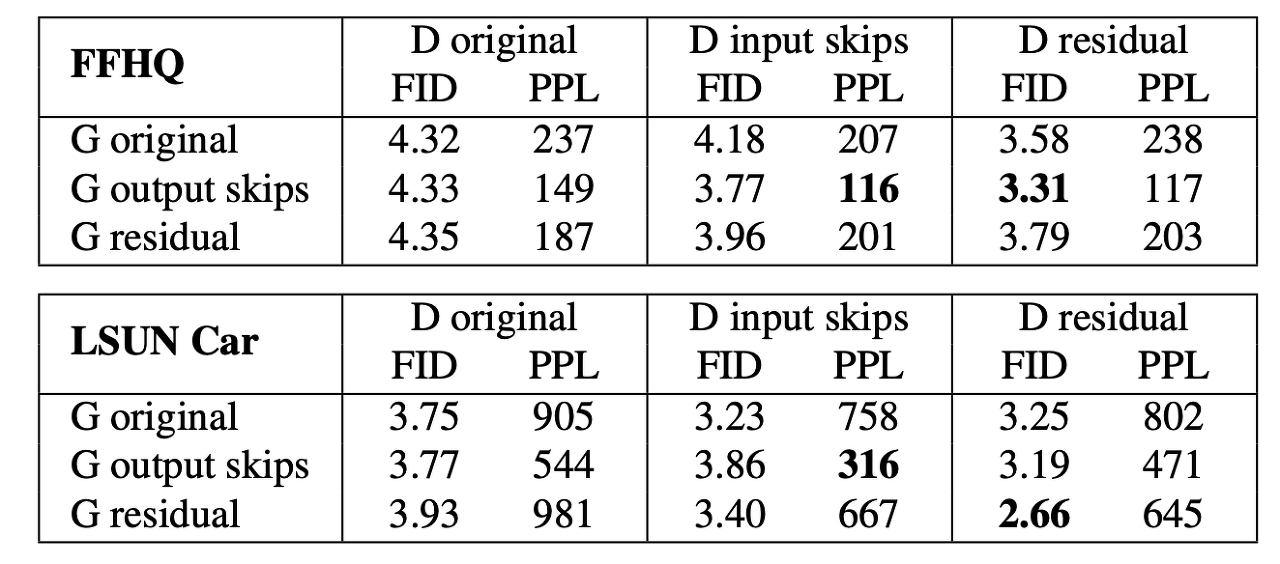
위 결과를 볼 때, (b)타입 생성자(Generator)를 사용하는 것은 PPL을 상당히 개선했고, (c)타입 판별자(Discriminator)를 사용했더니 FID를 개선했다고 한다. 그러므로 저자는 이 네트워크들을 채택했다.
Progressive Growing에서는 네트워크가 처음엔 저해상도 이미지를 생성하는 데 집중하였고, 그런 다음 점점 고해상도의 이미지를 생성하였다. 그러나 이 새 네트워크가 그런 류의 학습을 하는가? 아래 실험이 이를 증명한다.

(b) 타입 생성자(Generator)는 각 해상도의 생성된 이미지를 더하기 때문에 최종으로 생성된 이미지의 각 해상도의 기여도는 계산될 수 있다. 세로축은 각 해상도의 기여도를 가리키고 가로축은 학습 진전도를 가리킨다. 새로운 네트워크가 채택된 그림 (a)에서는 고해상도 쪽에 대한 기여도는 학습이 진전됨에 따라 증가하고 네트워크 크기가 증가하는 그림 (b)는 학습이 종료될 때, 고해상도 쪽의 기여도가 훨씬 증가했다.
새로운 메커니즘을 이용해 생성한 이미지는 다음과 같다. StyleGAN에선 눈과 이가 부자연스러운 반면, 새로운 메커니즘은 눈과 이가 얼굴 방향의 변화와 함께 자연스럽게 변하였다.


Path Length Regularization to smooth latent space
이제 잠재 공간의 지각적 매끄러움(perceputal smoothness)을 나타내는 PPL과 이미지 품질 사이에 상관관계가 있을 수 있다는 것을 알아냈기 때문에 우리는 이를 regularization term으로 통합하겠다. 수식은 다음과 같다. a는 상수고 y는 정규 분포로부터 생성된 랜덤 이미지이다.

이 정규화(regularization)는 생성자(generator)가 가능한 한 잠재 변수의 섭동(perturbation)으로 인한 변화를 최소 화하도록 한다. 학습은 첫 번째 항의 평균을 움직여 상수 a를 동적으로 바꾸면서 수행하여 학습 중 최적 값을 설정한다.
Results
첫 번째로 두 데이터 세트에 각 방법이 도입됨에 따른 점수 변화를 살펴보겠다.

본 글에서는 C에 대한 설명을 생략했지만 regularization term를 업데이트하는 것은 자주 수행할 필요가 없어 보이는데, 이를 "게으른(Lazy)" 정규화(regularization)이라고 한다. 결과를 살펴보면, 게을러도 결과는 나쁘지 않았다. F는 지금까지 설명한 방법 외에 네트워크 크기를 늘린 모델이다. 합성곱 연산(convolution) 안에 게으른 정규화(Lazy regularization)와 AdaIN을 통합하면 학습시간이 빨라졌다 (37 -> 61 images / sec). 그리고 이 덕분에 네트워크 규모를 키울 수 있었다 (31 images / sec).
다음으로, PPL의 분포를 살펴본다. PPL이 작을수록 생성된 이미지의 더 나은 품질을 의미하는 것이다. 그러므로 아래 히스토그램은 StyleGAN2의 품질이 향상됐다는 것을 보여준다.

다음으론, 생성된 이미지를 살펴본다. 매우 좋은 고품질의 이미지가 생성됐다.



마지막으로, 이는 잠재 공간으로 투영하는 방법으로 분석한 결과이다. 히스토그램은 LPIPS 거리 분포를 보여주는데, 이는 실제 이미지와 잠재 공간으로 투영한 후 생성자(Generator)에 한번 다시 통과한 이미지 사이의 거리이다. 히스토그램은 실제 이미지와 StyleGAN, StyleGAN2의 결과를 보여주고 시각화한다. (실제 이미지 또한 인공적으로 잠재 공간으로 떨어졌다.)

StyleGAN2가 StyleGAN과 실제 이미지보다 잠재 공간에서 더 잘 투영됨을 볼 수 있다. 이는 아마도 PPL을 위한 regularization term을 통한 잠재 공간의 매끄러움(smoothing) 때문일 것이다. 아래 그림은 다음 과정을 거친 실제 이미지와 재구성된 이미지(reconstruction images)를 보여준다. 실제 이미지 -> 잠재 공간에 투영 -> 생성자(Generator). StyleGAN에선, 재구성된 이미지(reconstruction images)가 몇몇 장소에서 실제 이미지와 다른 특징 몇 가지를 지녔지만 StyleGAN2에선 꽤 잘 재구성된 것을 볼 수 있다.

Conclusion
StyleGAN2는 정규화(normalization)를 개선하고 매끄러운(smooth) 잠재 공간을 위해 제약(constraints)을 추가하여 이미지 품질을 개선하였다. 그러나 8개의 GPUs (V100)을 사용했음에도, FFHQ 데이터셋을 사용할 땐, 9일, LSUN CAR 데이터셋에서는 13일이 소요됐다. BigGANs와 다른 모델은 더 큰 모델의 효과를 입증했다.
Reference
https://arxiv.org/abs/1812.04948 (A Style-Based Generator Architecture for Generative Adversarial Networks)
https://arxiv.org/pdf/1912.04958.pdf (Analyzing and Improving the Image Quality of StyleGAN)
https://medium.com/analytics-vidhya/from-gan-basic-to-stylegan2-680add7abe82 (From GAN basic to StyleGAN2)