
티스토리 뷰
공부한 내용 정리/인공지능
[논문 리뷰]EfficientNetV2: Smaller Models and Faster Training
ProWiseman 2023. 1. 19. 23:52들어가며
본 글은 논문 EfficientNetV2: Smaller Models and Faster Training을 리뷰한 글입니다.
내용
기존 문제
GPT3와 같이 모델과 학습 데이터가 커질수록 few shot learning에 효과적이나 수 주의 학습 시간과 수천 개의 GPU가 필요하여 개선과 재학습을 어렵게 한다.
기존 EfficientNet의 문제
- 큰 이미지 사이즈에서의 학습이 느리다.
- Depthwise convolution은 초기 레이어에서 느리다.
- 모든 단계에서 동일하게 scaling up 하는 것은 최선이 아니다.
키 아이디어
- Fused-MBConv 연산자를 적용한다.
- 이미지 크기를 증가시키며 점점 강한 규제를 적용한다.
- Training-aware NAS로 최적의 하이퍼파라미터를 탐지한다.
- 후기 스테이지로 갈수록 레이어를 더 쌓는 불균일 스케일링 전략을 사용한다.
EfficientNet
EfficientNet은 FLOPs와 파라미터 효율을 최적화한 모델이다.
주요 내용
- NAS를 통해 베이스라인인 EfficientNet-B0를 찾았다.
- Scale up을 통해 B1-B7 모델을 찾았다.
EfficientNet 논문의 목표는 파라미터 효율성을 유지시키며 학습 속도를 향상시키는 것이었다.

학습 효율에 대한 이해
- 학습 이미지가 커지면 학습 속도도 느려진다.
- 이미지가 작으면 연산량이 줄어들고 그래야 배치 사이즈를 늘릴 수 있기 때문이다.
- Depthwise convolution은 초기 레이어에서는 느리나 후기 레이어에서 효과적이다.
- Depthwise convolution은 일반적인 합성곱 연산보다 파라미터와 FLOPs가 적으나 현대 가속기(GPU로 이해함)를 완전히 활용하진 못한다.
- 이는 Fused-MBConv를 활용하면 훨씬 낫다. 그러나 파라미터와 FLOPs가 늘어나고 학습이 느려진다.
- 따라서 MBConv와 Fused-MBConv를 적절히 조합하여야 한다.
- 모든 스테이지에 똑같은 scaling up을 적용하는 것은 최선이 아니다.
- 기존 EfficientNet은 모든 스테이지에 단순한 scaling rule을 적용하여 동일하게 scale up을 해주었다.
- 그러나 모든 스테이지가 학습 속도와 파라미터 효율에 동일하게 기여하지 않는다.
- 이 논문에선 후기 스테이지로 갈수록 레이어를 더 쌓는 불균일 스케일링 전략을 사용한다.
Training-Aware NAS
NAS를 통해 정확도, 파라미터 효율, 현대 가속기에서의 학습 효율의 최적화를 진행한다.
백본으로 EfficientNet을 사용하며 탐색할 대상은 다음과 같다.
- convolution operation types {MBConv, Fused-MBConv}
- number of layers, kernel size {3×3, 5×5}
- expansion ratio {1, 4, 6}
1000가지 모델을 각각 크기를 줄인 이미지로 10 에폭씩 학습하며 정확도와 학습 속도, 파라미터 크기의 곱을 구한 것을 보상으로 사용했다.
그리하여 찾은 EfficientNetV2-S의 모델은 다음 표와 같다.
Scaling
다음의 조건 하에 스케일 업을 진행했다.
- 너무 큰 이미지는 OOM을 유발하거나 학습 속도에 오버헤드를 유발하기에 추론 이미지 사이즈의 최대를 480으로 제한했다.
- 네트워크 수행력을 런타임 오버헤드 없이 증가시키기 위해 휴리스틱(연구자 임의로 했다고 이해함)으로 층이 깊어질 수 있도록 더 많은 레이어를 추가해 주었다.
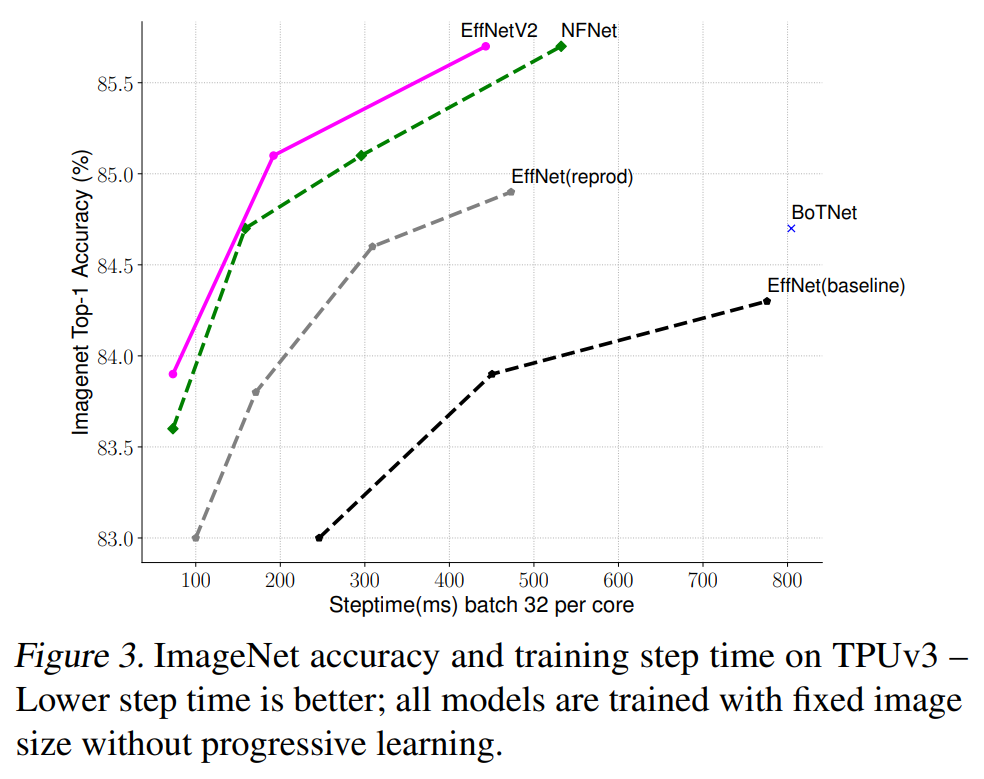
Progressive Learning
앞서 서술했듯 이미지의 크기는 학습 효율에 중요한 역할을 한다. 여러 작업들이 이미지 크기를 학습 중에 동적으로 바꾸지만 이는 정확도를 떨어뜨린다.
본 논문에선 이러한 정확도 하락이 불균형한 규제로부터 온다고 가설을 세웠다.
- 서로 다른 이미지 크기로 학습을 할 때는 적절히 규제의 강도를 조절해야 한다.
- 이 논문에선 같은 네트워크 일지라도 작은 이미지엔 약한 규제, 큰 이미지엔 강한 규제를 적용한다.
- 규제는 Dropout, RandAugment, Muxup의 파라미터를 조절해 가며 강도를 조절한다.
이러한 경향은 아래 표에서 확인할 수 있다.
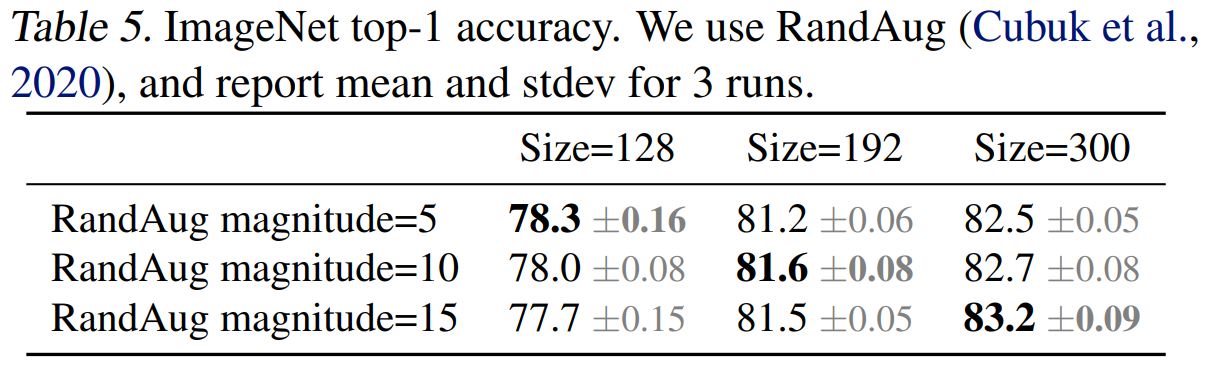
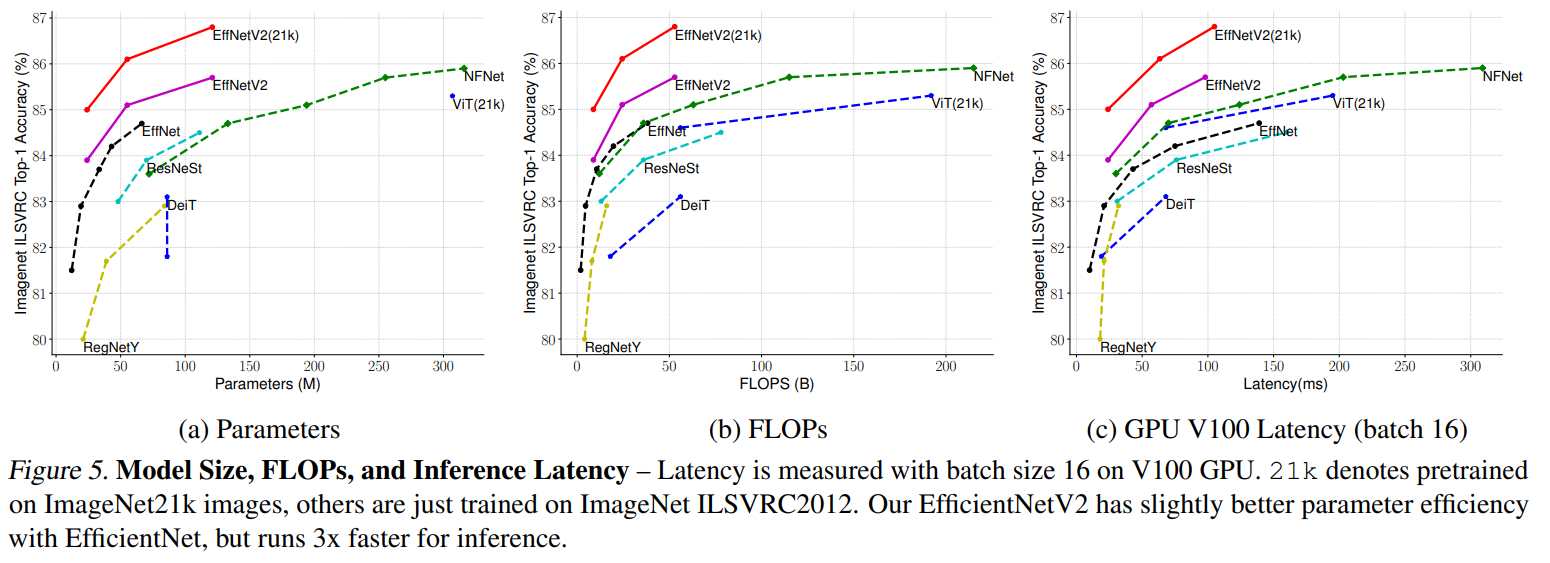
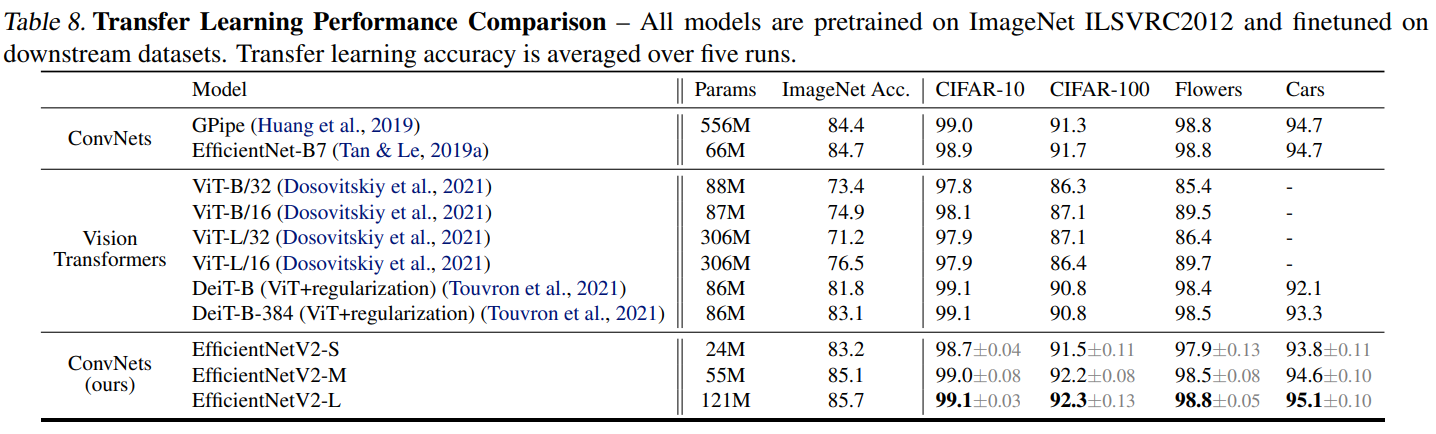
결과
'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| [논문 리뷰]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2023.02.07 |
|---|---|
| [논문 리뷰]You Only Look Once: Unified, Real-Time Object Detection (0) | 2023.01.22 |
| [논문 리뷰]Sequence to Sequence Learning with Neural Networks (0) | 2023.01.19 |
| [논문 리뷰]Deep contextualized word representations (1) | 2023.01.16 |
| [TinyML]Tiny Machine Learning: The Next AI Revolution (0) | 2023.01.14 |