
티스토리 뷰
들어가며
본 글은 저의 TinyML 공부를 위해 towardsdatascience에 작성된 Tiny Machine Learning: The Next AI Revolution을 번역 및 재구성 한 글입니다.
내용
이 글에선 tiny machine learning(이하 초소형 머신러닝)의 아이디어와 미래의 잠재력을 소개한다.

Intorduction
최근 10년간 프로세서 속도의 향상과 빅데이터의 출현을 머신러닝 알고리즘의 크기가 커졌다. 초기 모델은 로컬 머신의 CPU에서 돌릴 수 있을 정도로 작았지만 금방 더 큰 데이터셋을 다루기 위해 GPU가 필수가 됐다. 이 시기에도 여전히 하나의 머신에서 돌릴 수 있었다. 최근에는 8개의 GPU 파워를 담을 수 있을 정도의 ASICs와 TPU가 개발되었고, 이런 장치는 모델을 점점 더 키우려는 시도 속에서 여러 시스템에 걸쳐 학습을 분산하는 기능으로 보강되었다. 이는 GPT-3의 등장으로 정점을 찍었다. GPT-3는 850억 개인 사람의 뉴런의 두 배나 되며 GPT-3 이전 가장 큰 모델보다 10배 더 많은 1750억 개의 뉴런을 보유하며 학습에 1,000만 달러의 비용과 3 GWh의 전기가 소모될 것으로 추측된다고 한다. 이 점은 AI 산업의 점점 더 커지는 탄소 발자국에 대한 비판의 목소리도 이끌어냈지만, AI 커뮤니티에 에너지 효율적인 연산에 관한 관심을 활성화하는 데 도움이 되기도 했다.
초소형 머신러닝은 머신러닝과 임베디드 IoT 장치의 교집합이다. 이 분야는 많은 산업에 혁신할 잠재력을 가졌다. 초소형 머신러닝의 주요 수혜 산업은 엣지 컴퓨팅(edge computing)과 에너지 효율성 관련 컴퓨팅(energy-efficient computing)이다. IoT의 전통적인 아이디어는 데이터가 로컬 디바이스에서 클라우드로 처리를 위해 전송되는 것이었다. 그러나 이는 privacy, latency, storage, energy efficiency 등과 같은 문제가 있다.
Privacy
데이터를 전송하는 것은 스니핑 같은 개인정보 침해를 유발할 수 있고 본질적으로 클라우드와 같이 단일 위치에 보관될 때 더 취약하다. 데이터를 온디바이스에 보관하고 통신을 최소화하며 보안을 개선하고 개인정보를 보호할 수 있다.
Latency
아마존의 Alexa와 같은 표준 IoT 기기의 경우 데이터 처리를 위해 데이터를 클라우드에 보내고 알고리즘에 따라 처리한 결과를 반환받는다. 이런 의미에서 IoT 기기는 단순히 편리한 클라우드 모델의 게이트웨이로 볼 수 있다. IoT 기기는 꽤나 멍청하고 결과물을 생산하는데 인터넷 속도에 의존하게 된다. 자동 음성 인식 같은 알고리즘이 탑재된 지능형 IoT 기기의 경우 외부와의 통신에 대한 의존도가 줄어들기에 레이턴시 또한 줄어든다.
Storage
많은 IoT 기기의 경우 이들이 얻는 데이터는 가치가 없다. 예를 들어 보안 카메라의 경우 하루 대부분의 시간 동안 아무 일도 일어나지 않기에 그 시간 동안의 영상은 필요가 없다. 필요할 때만 활성화되는 지능적 시스템이 있으면 저장공간이 덜 필요해지고 클라우드에 데이터를 전송할 필요성도 줄어들게 된다.
Energey Efficiency
데이터를 전송하는 것은 온보드 컴퓨팅보다 훨씬 더 에너지 집약적이다. 따라서 IoT 시스템 자체에서 데이터를 처리하도록 개발하는 것이 가장 에너지 효율적인 방법이다. 그래서 나온 개념이 "데이터 중심(data-centric)"연산이다. (반대 개념으로 클라우드의 "연산 중심(compute-centric)이 있다.)
이러한 문제들은 엣지 디바이스 자체에서 처리를 수행하는 에지 컴퓨팅의 발전을 이끌어냈다. 엣지 디바이스는 메모리, 연산 능력, 전력과 같은 자원들이 극도로 제한돼 있어 보다 효율적인 알고리즘, 데이터 구조, 연산 방법의 발전으로 이어졌다. 이러한 발전은 더 큰 모델에도 적용할 수 있어 규모에 따라 머신러닝 모델의 효율성을 모델의 정확도에 영향 없이 증가시킬 수 있다. 예를 들어 마이크로소프트의 Bonsai 알고리즘은 2KB의 크기로 40MB의 kNN 알고리즘이나 4MB의 신경망보다 훨씬 좋은 퍼포먼스를 보여준다. 이렇게 작은 모델은 아두이노 우노에서도 돌릴 수 있다. 다시 말해 머신러닝 모델을 5 달러짜리 마이크로 컨트롤러에 빌드할 수 있단 말이다.
앞서 살펴본 것과 같이 머신러닝은 연산 중심, 데이터 중심의 두 개의 패러다임으로 분기될 수 있다. 연산 중심 패러다임에선 데이터를 쌓고 데이터 센터에 있는 인스턴스로 분석한다. 반면 데이터 중심 패러다임은 데이터 원본이 로컬에서 처리가 완료된다. 연산 중심의 패러다임은 정점을 향해 빠르게 움직이고 있는 반면 데이터 중심의 패러다임은 이제 막 시작됐다. IoT 기기와 임베디드 머신러닝 모델은 현대에 점점 더 어디서나 볼 수 있게 되고 있다. 지금부터 초소형 머신러닝이 어떻게 작동하는지와 현재와 미래의 애플리케이션에 대해 더 자세히 설명할 것이다.
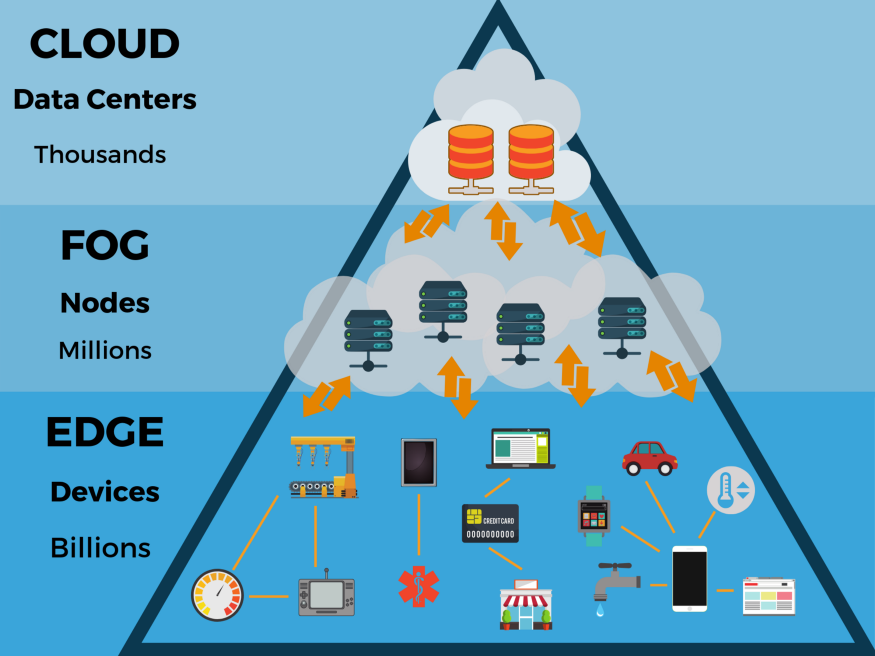
How TinyML Works
초소형 머신러닝 알고리즘은 전통적인 머신러닝 모델과 상당히 유사하게 작동한다. 특히 모델은 보통 유저의 컴퓨터나 클라우드에서 학습된다. 학습 후가 진짜 초소형 머신러닝의 시작이다. 이러한 과정을 deep compression이라 부른다.

Model Distillation
학습 후에 모델은 가지치기(pruning)와 지식 증류(knowledge distillation)와 같은 기술을 통해 더 가벼운 표현으로 모델을 생성하는 식으로 변경된다. 지식 증류의 기저에 깔려있는 아이디어는 큰 모델이 희소성(sparsity)과 중복성(redundancy)을 갖고 있다는 것이다. 큰 네트워크가 높은 표현 용량이 높지만 네트워크 용량이 포화되지 않으면(네트워크 전체를 활용한다는 뜻으로 이해함) 표현 용량이 더 적은(즉, 더 적은 뉴련의) 네트워크로 표현될 수 있다. Hinton et al. (2015)에서 student 모델로 전달될 teacher 모델에 포함된 정보(embedded information)를 dark knowledge라고 했다.
아래 그림은 지식 증류의 과정의 도식이다.

다이어그램에선 teacher은 CNN 모델을 학습하고 이의 정보를 더 적은 파라미터를 가진 작은 student CNN 모델에 전사하는 것이 과제다. 이러한 과정이 지식 증류이고 이를 통해 같은 정보를 더 작은 네트워크에 보관할 수 있다. 이러한 네트워크 압축 방식은 메모리가 제한된 기기에서 사용될 수 있다.
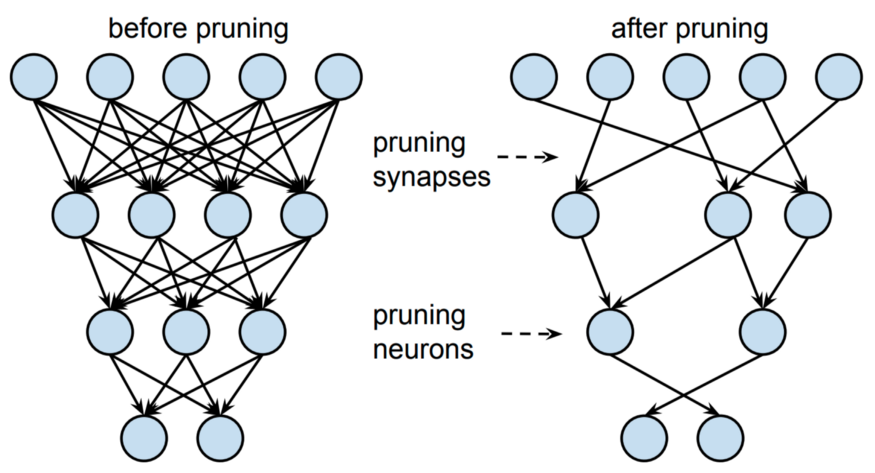
가지치기도 유사하게 모델의 표현을 더욱 간결하게 만들 수 있다. 가지치기는 아웃풋 예측에 적은 유용성을 제공하는 뉴런을 제거하는 것이다. 이는 보통 작은 신경 가중치에 행해지는 반면 더 큰 가중치는 추론 중 더 큰 중요성으로 인해 유지된다.
Quantization
증류 후에 모델은 임베디드 기기의 아키텍처와 호환되는 형식으로 사후 훈련을 통해 양장화된다. 8-bit 연산의 ATmega328P 마이크로컨트롤러를 사용하는 아두이노 우노에서 모델을 돌리기 위해선 모델의 가중치가 8-bit의 정수로 저장될 필요가 있다. 모델을 양자화함으로써 기존 32-bit에서 8-bit로 가중치의 용량이 4배 줄고 정확도엔 미미한 영향(보통 1~3%)만 미친다.

부동 소수점이 날아가는 양자화 오차 때문에 양자화 도중 정보의 손실이 발생한다. 이를 다루기 위해 quantization-aware(QA) 학습이 대안으로 제시된다. QA 학습은 양자화된 기기에서 가능한 값만을 사용하도록 네트워크에 제한을 걸고 학습하는 방식이다.
Huffman Encoding
인코딩은 최대로 효율적인 방식으로 데이터를 저장하여 모델 크기를 추가로 줄이기 위해 선택적으로 수행되는 단계이다. 이 과정에선 보통 Huffman encoding이 사용된다.
Compliation
모델이 양자화되고 인코딩 되면 일종의 가벼운 신경망 인터프리터로 인터프리트 될 수 있는 형식으로 변환된다. 가장 대중적인 방식은 TF Lite (~500 KB)와 TF Lite Micro (~20 KB)이다. 그 후 모델은 C나 C++로 컴파일되고 온디바이스 인터프로터로 실행된다.

초소형 머신러닝 기술의 대부분은 마이크로컨트롤러의 복잡한 세계를 다루는 데로부터 온다. TF Lite와 TF Lite Micro는 불필요한 기능을 지워 굉장히 작다. 지워진 기능 중에는 디버깅이나 시각화 같은 기능도 포함되기에 배포 중 에너가 나도 무엇이 일어나는지 알아차리기 어렵다.
또한 모델은 장치에 저장되어야 하는 한편 추론도 할 수 있어야 한다. 이는 마이크로컨트롤러의 메모리가 다음의 것들을 실행시킬 수 있을 만큼 충분히 커야 한다는 것을 의미한다.
- 운영체제와 라이브러리
- TF Lite와 같은 신경망 인터프리터
- 저장된 신경 가중치와 신경 아키텍처
- 추론 중 중간 결과
따라서 양자화 알고리즘의 최대 메모리 사용량은 메모리 사용량, 단일 곱셈-누산기(MACs), 정확도 등과 함께 초소형 머신러닝 연구 논문에서 자주 인용된다.
The Next AI Revolution
어떤 머신러닝 종사자들은 모델의 사이즈를 키우는 한편 머신러닝 알고리즘을 더욱 메모리, 연산, 에너지 효율적으로 만드는 새로운 트렌드 또한 성장 중이다. 초소형 머신러닝은 아직 초기 단계이고 이 주제에 대한 전문가도 적다. 이 분야는 빠르게 성장 중이고 향후 몇 년 내에 업계에서 새롭고 중요한 인공지능 애플리케이션이 될 것이다.
마치며
본 글은 제 임의대로 축약하고 의역하며 해석하였고 물론 오역이 있을 수 있습니다. 더 상세하고 정확한 내용을 원하시는 분들은 원글을 보시고 또 원글에서 저자는 이 분야에 관심이 있으면 References에 수록된 논문들을 찾아 읽어보길 추천했으니 한 번 찾아보시는 것도 좋을 듯합니다.
'공부한 내용 정리 > 인공지능' 카테고리의 다른 글
| [논문 리뷰]EfficientNetV2: Smaller Models and Faster Training (0) | 2023.01.19 |
|---|---|
| [논문 리뷰]Sequence to Sequence Learning with Neural Networks (0) | 2023.01.19 |
| [논문 리뷰]Deep contextualized word representations (1) | 2023.01.16 |
| StyleGAN / StyleGAN2 (2) | 2020.08.08 |
| CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms (3) | 2020.08.08 |